Часто став з'являтися питання: чому немає GPU прискорення в програмі Adobe Media Encoder CC? А то що Adobe Media Encoder використовує GPU прискорення, ми з'ясували, а також відзначили нюанси його використання. Також зустрічається твердження: що в програмі Adobe Media Encoder CC прибрали підтримку GPU прискорення. Це помилкова думка і випливає з того, що основна програма Adobe Premiere Pro CC тепер може працювати без прописаної і рекомендованої відеокарти, а для включення GPU движка в Adobe Media Encoder CC, відеокарта повинна бути обов'язково прописана в документах: cuda_supported_cards або opencl_supported_cards. Якщо з чіпсетами nVidia все зрозуміло, просто беремо ім'я чіпсета і вписуємо його в документ cuda_supported_cards. Те при використанні відеокарт AMD прописувати треба не ім'я чіпсета, а кодову назву ядра. Отже, давайте на практиці перевіримо, як на ноутбуці ASUS N71JQ з дискретною графікою ATI Mobility Radeon HD 5730 включити GPU движок в Adobe Media Encoder CC. Технічні дані графічного адаптера ATI Mobility Radeon HD 5730 показуються утилітою GPU-Z:
Запускаємо програму Adobe Premiere Pro CC і включаємо движок: Mercury Playback Engine GPU Acceleration (OpenCL).

Три DSLR відео на таймлайн, один над одним, два з них, створюють ефект картинка в картинці.

Ctrl + M, вибираємо пресет Mpeg2-DVD, прибираємо чорні смуги з боків за допомогою опції Scale To Fill. Включаємо також підвищений якість для тестів без GPU: MRQ (Use Maximum Render Quality). Натискаємо на кнопку: Export. Завантаження процесора до 20% і оперативної пам'яті 2.56 Гбайт.

Завантаження GPU чіпсета ATI Mobility Radeon HD 5730 становить 97% і 352Мб бортовий відеопам'яті. Ноутбук тестувався при роботі від акумулятора, тому графічне ядро / пам'ять працюють на знижених частотах: 375/810 МГц.
Підсумкове час прорахунку: 1 хвилина і 55 секунд(Вкл / викл. MRQ при використанні GPU движка, не впливає на підсумкову час прорахунку).
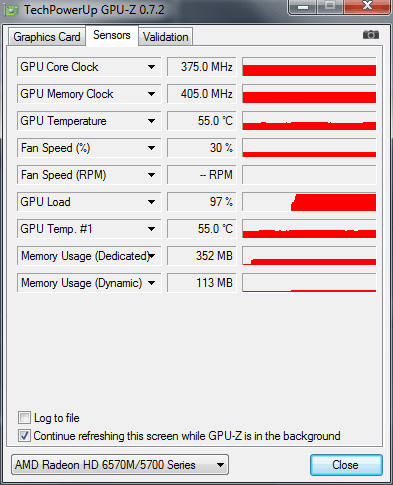
При встановленій Галці Use Maximum Render Quality тепер натискаємо на кнопку: Queue.


Тактові частоти процесора при роботі від акумулятора: 930МГц.


Запускаємо AMEEncodingLog і дивимося підсумкове час прорахунку: 5 хвилин і 14 секунд.

Повторюємо тест, але вже при знятої Галці Use Maximum Render Quality, натискаємо на кнопку: Queue.

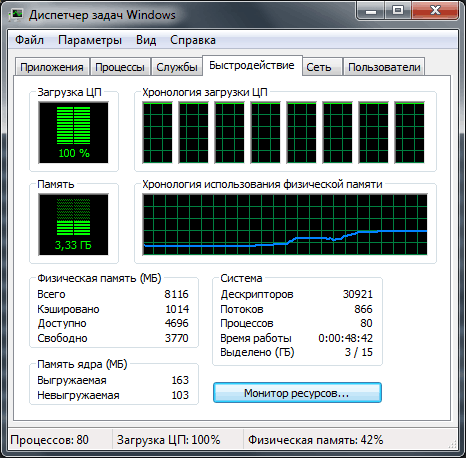
Підсумкове час прорахунку: 1 хвилина і 17 секунд.

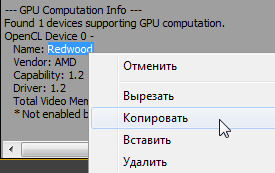
Тепер включимо GPU движок в Adobe Media Encoder CC, запускаємо програму Adobe Premiere Pro CC, натискаємо комбінацію клавіш: Ctrl + F12, виконуємо Console> Console View і в поле Command вбиваємо GPUSniffer, натискаємо Enter.

Виділяємо і копіюємо ім'я в GPU Computation Info.
В директорії програми Adobe Premiere Pro CC відкриваємо документ opencl_supported_cards, і в алфавітному порядку вбиваємо кодове ім'я чіпсета, Ctrl + S.
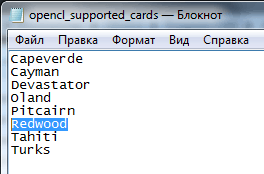
Натискаємо на кнопку: Queue, і отримуємо GPU прискорення прорахунку проекту Adobe Premiere Pro CC в Adobe Media Encoder CC.
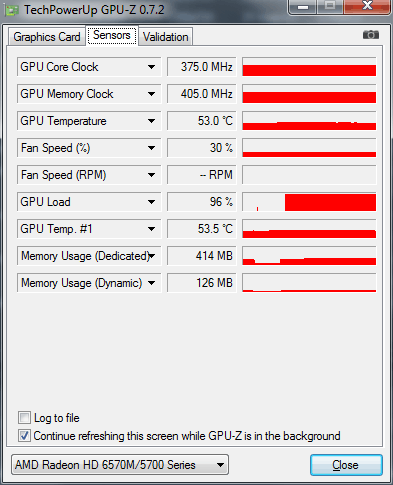
Підсумкове час: 1 хвилина і 55 секунд.

Підключаємо ноутбук до розетки, і повторюємо результати прорахунків. Queue, галка MRQ знята, без включення движка, завантаження оперативної пам'яті трохи підросла:

Тактові частоти процесора: 1.6ГГц при роботі від розетки і включення режиму: Висока продуктивність.

Підсумкове час: 46 секунд.

Включаємо движок: Mercury Playback Engine GPU Acceleration (OpenCL), як видно від мережі ноутбучная відеокарта працює на своїх базових частотах, завантаження GPU в Adobe Media Encoder CC досягає 95%.
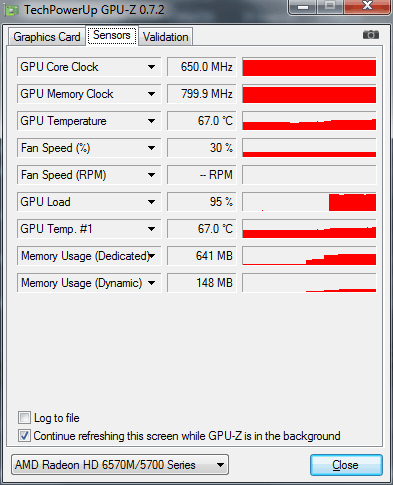
Підсумкове час прорахунку, знизилося з 1 хвилини 55 секунд, до 1 хвилини і 5 секунд.

* Для візуалізації в Adobe Media Encoder CC тепер використовується графічний процесор (GPU). Підтримуються стандарти CUDA і OpenCL. В Adobe Media Encoder CC, движок GPU використовується для наступних процесів візуалізації:
- Зміна чіткості (від високої до стандартної і навпаки).
- Фільтр тимчасового коду.
- Перетворення формату пікселів.
- Расперемеженіе.
Якщо візуалізується проект Premiere Pro, в AME використовуються установки візуалізації з GPU, задані для цього проекту. При цьому будуть використані всі можливості візуалізації з GPU, реалізовані в Premiere Pro. Для візуалізації проектів AME використовується обмежений набір можливостей візуалізації з GPU. Якщо послідовність візуалізується з використанням оригінальної підтримки, застосовується настройка GPU з AME, настройка проекту ігнорується. В цьому випадку всі можливості візуалізації з GPU Premiere Pro використовуються безпосередньо в AME. Якщо проект містить VST сторонніх виробників, використовується настройка GPU проекту. Послідовність кодується за допомогою PProHeadless, як і в більш ранніх версіях AME. Якщо прапорець Enable Native Premiere Pro Sequence Import (Дозволити імпорт вихідної послідовності Premiere Pro) знятий, завжди використовується PProHeadless і настройка GPU.
Читаємо про прихований розділ на системному диску ноутбука ASUS N71JQ.
Обчислення на графічних процесорах
Технологія CUDA (англ. Compute Unified Device Architecture) - програмно-апаратна архітектура, що дозволяє робити обчислення з використанням графічних процесорів NVIDIA, що підтримують технологію GPGPU (довільних обчислень на відкритих). Архітектура CUDA вперше з'явилися на ринку з виходом чіпа NVIDIA восьмого покоління - G80 і присутня у всіх наступних серіях графічних чіпів, які використовуються в родинах прискорювачів GeForce, ION, Quadro і Tesla.
CUDA SDK дозволяє програмістам реалізовувати на спеціальному спрощеному діалекті мови програмування Сі алгоритми, здійснимі на графічних процесорах NVIDIA і включати спеціальні функції в текст програми на Сі. CUDA дає розробнику можливість на свій розсуд організовувати доступ до набору інструкцій графічного прискорювача і управляти його пам'яттю, організовувати на ньому складні паралельні обчислення.
Історія
У 2003 р Intel і AMD брали участь у спільній гонці за самий потужний процесор. За кілька років в результаті цієї гонки тактові частоти істотно зросли, особливо після виходу Intel Pentium 4.
Після приросту тактових частот (між 2001 і 2003 рр. Тактова частота Pentium 4 подвоїлася з 1,5 до 3 ГГц), а користувачам довелося задовольнятися десятими частками гігагерц, які вивели на ринок виробники (з 2003 до 2005 гг.тактовие частоти збільшилися 3 до 3,8 ГГц).
Архітектури, оптимізовані під високі тактові частоти, та ж Prescott, так само стали зазнавати труднощів, і не тільки виробничі. Виробники чіпів зіткнулися з проблемами подолання законів фізики. Деякі аналітики навіть пророкували, що закон Мура перестане діяти. Але цього не сталося. Оригінальний сенс закону часто спотворюють, однак він стосується числа транзисторів на поверхні кремнієвого ядра. Довгий час підвищення числа транзисторів в CPU супроводжувалося відповідним зростанням продуктивності - що і призвело до спотворення сенсу. Але потім ситуація ускладнилася. Розробники архітектури CPU підійшли до закону скорочення приросту: число транзисторів, що було потрібно додати для потрібного збільшення продуктивності, ставало все більшим, заводячи в глухий кут.
Причина, по якій виробникам GPU не зіткнулися з цією проблемою дуже проста: центральні процесори розробляються для отримання максимальної продуктивності на потоці інструкцій, які обробляють різні дані (як цілі числа, так і числа з плаваючою комою), виробляють випадковий доступ до пам'яті і т. д. До сих пір розробники намагаються забезпечити більший паралелізм інструкцій - тобто виконувати якомога більше число інструкцій паралельно. Так, наприклад, з Pentium з'явилося суперскалярное виконання, коли при деяких умовах можна було виконувати дві інструкції за такт. Pentium Pro отримав позачергове виконання інструкцій, що дозволило оптимізувати роботу обчислювальних блоків. Проблема полягає в тому, що у паралельного виконання послідовного потоку інструкцій є очевидні обмеження, тому сліпе підвищення числа обчислювальних блоків не дає виграшу, оскільки більшу частину часу вони все одно будуть простоювати.
Робота GPU відносно проста. Вона полягає в прийнятті групи полігонів з одного боку і генерації групи пікселів з іншого. Полігони і пікселі незалежні один від одного, тому їх можна обробляти паралельно. Таким чином, в GPU можна виділити велику частину кристала на обчислювальні блоки, які, на відміну від CPU, будуть реально використовуватися.

GPU відрізняється від CPU не тільки цим. Доступ до пам'яті в GPU дуже пов'язаний - якщо зчитується тексель, то через кілька тактів буде зчитуватися сусідній тексель; коли записується піксель, то через кілька тактів буде записуватися сусідній. Розумно організовуючи пам'ять, можна отримати продуктивність, близьку до теоретичної пропускної здатності. Це означає, що GPU, на відміну від CPU, не потрібно величезної кешу, оскільки його роль полягає в прискоренні операцій текстурирования. Все, що потрібно, це кілька кілобайт, що містять кілька текселей, використовуваних в білінійних і трикутних фільтрах.
Перші розрахунки на GPU
Найперші спроби такого застосування обмежувалися використанням деяких апаратних функцій, таких, як растеризация і Z-буферизація. Але в нинішньому столітті, з появою шейдеров, почали прискорювати обчислення матриць. У 2003 р на SIGGRAPH окрема секція була виділена під обчислення на GPU, і вона отримала назву GPGPU (General-Purpose computation on GPU) - універсальні обчислення на GPU).
Найбільш відомий BrookGPU - компілятор потокового мови програмування Brook, створений для виконання неграфічних обчислень на GPU. До його появи розробники, що використовують можливості відеочіпів для обчислень, вибирали один з двох поширених API: Direct3D або OpenGL. Це серйозно обмежувало застосування GPU, адже в 3D графіку використовуються шейдери і текстури, про які фахівці з паралельного програмування знати не зобов'язані, вони використовують потоки і ядра. Brook зміг допомогти в полегшенні їх завдання. Ці потокові розширення до мови C, розроблені в Стенфордському університеті, приховували від програмістів тривимірний API, і представляли відеочіп у вигляді паралельного співпроцесора. Компілятор обробляв файл.br з кодом C ++ і розширеннями, виробляючи код, прив'язаний до бібліотеки з підтримкою DirectX, OpenGL або x86.
Поява Brook викликав інтерес у NVIDIA і ATI і надалі, відкрив цілий новий його сектор - паралельні обчислювачі на основі відеочіпів.
Надалі, деякі дослідники з проекту Brook перейшли в команду розробників NVIDIA, щоб представити програмно-апаратну стратегію паралельних обчислень, відкривши нову частку ринку. І головною перевагою цієї ініціативи NVIDIA стало те, що розробники відмінно знають всі можливості своїх GPU до дрібниць, і у використанні графічного API немає необхідності, а працювати з апаратним забезпеченням можна безпосередньо за допомогою драйвера. Результатом зусиль цієї команди стала NVIDIA CUDA.
Області застосування паралельних розрахунків на GPU
При перенесенні обчислень на GPU, у багатьох задачах досягається прискорення в 5-30 разів, у порівнянні з швидкими універсальними процесорами. Найбільші цифри (близько 100-кратного прискорення і навіть більше!) Досягаються на коді, який не дуже добре підходить для розрахунків за допомогою блоків SSE, але цілком зручний для GPU.
Це лише деякі приклади прискорень синтетичного коду на GPU проти SSE-векторизованних коду на CPU (за даними NVIDIA):
Флуоресцентна мікроскопія: 12x.
Молекулярна динаміка (non-bonded force calc): 8-16x;
Електростатика (пряме і багаторівневе підсумовування Кулона): 40-120x і 7x.
Таблиця, яку NVIDIA, показує на всіх презентаціях, в якій показується швидкість графічних процесорів щодо центральних.

Перелік основних додатків, в яких застосовуються обчислення на GPU: аналіз і обробка зображень і сигналів, симуляція фізики, обчислювальна математика, обчислювальна біологія, фінансові розрахунки, бази даних, динаміка газів і рідин, криптографія, адаптивна променева терапія, астрономія, обробка звуку, біоінформатика , біологічні симуляції, комп'ютерний зір, аналіз даних (data mining), цифрове кіно і телебачення, електромагнітні симуляції, геоінформаційні системи, військові застосування, гірське планування, молекулярна динаміка, магнітно-резонансна томографія (MRI), нейромережі, океанографічні дослідження, фізика частинок, симуляція згортання молекул білка, квантова хімія, трасування променів, візуалізація, радари, гідродинамічний моделювання (reservoir simulation), штучний інтелект, аналіз супутникових даних, сейсмічна розвідка, хірургія, ультразвук, відеоконференції.
Переваги та обмеження CUDA
З точки зору програміста, графічний конвеєр є набором стадій обробки. Блок геометрії генерує трикутники, а блок растеризації - пікселі, які відображаються на моніторі. Традиційна модель програмування GPGPU виглядає наступним чином:

Щоб перенести обчислення на GPU в рамках такої моделі, потрібен спеціальний підхід. Навіть поелементне складання двох векторів зажадає відтворення фігури на екрані або у позаекранного буфер. Фігура растеризуются, колір кожного пікселя обчислюється за заданою програмою (піксельному шейдеру). Програма зчитує вхідні дані з текстур для кожного пікселя, складає їх і записує у вихідний буфер. І всі ці численні операції потрібні для того, що в звичайній мові програмування записується одним оператором!
Тому, застосування GPGPU для обчислень загального призначення має обмеження у вигляді занадто великої складності навчання розробників. Та й інших обмежень досить, адже піксельний шейдер - це всього лише формула залежності підсумкового кольору пікселя від його координати, а мова піксельних шейдеров - мова запису цих формул з Сі-подібним синтаксисом. Ранні методи GPGPU є хитрим трюком, що дозволяє використовувати потужність GPU, але без всякого зручності. Дані там представлені зображеннями (текстурами), а алгоритм - процесом растеризації. Потрібно особливо відзначити і вельми специфічну модель пам'яті і виконання.
Програмно-апаратна архітектура для обчислень на GPU компанії NVIDIA відрізняється від попередніх моделей GPGPU тим, що дозволяє писати програми для GPU на справжньому мовою Сі зі стандартним синтаксисом, покажчиками і необхідністю в мінімумі розширень для доступу до обчислювальних ресурсів відеочіпів. CUDA не залежить від графічних API, і володіє деякими особливостями, призначеними спеціально для обчислень загального призначення.
Переваги CUDA перед традиційним підходом до GPGPU обчислень
CUDA забезпечує доступ до розділяється між потоками пам'яті розміром в 16 Кб на мультипроцессор, яка може бути використана для організації кеша з широкою смугою пропускання, в порівнянні з текстурними вибірками;
Більш ефективна передача даних між системною і відеопам'яттю;
Відсутність необхідності в графічних API з надмірністю і накладними витратами;
Лінійна адресація пам'яті, і gather і scatter, можливість запису по довільним адресами;
Апаратна підтримка цілочисельних і бітових операцій.
Основні обмеження CUDA:
Відсутність підтримки рекурсії для виконуваних функцій;
Мінімальна ширина блоку в 32 потоку;
Закрита архітектура CUDA, що належить NVIDIA.
Слабкими місцями програмування за допомогою попередніх методів GPGPU є те, що ці методи не використовують блоки виконання вершинних шейдеров в попередніх неуніфікованих архитектурах, дані зберігаються в структурах, а виводяться у позаекранного буфер, а багатопрохідні алгоритми використовують піксельні шейдерниє блоки. У обмеження GPGPU можна включити: недостатньо ефективне використання апаратних можливостей, обмеження пропускною здатністю пам'яті, відсутність операції scatter (тільки gather), обов'язкове використання графічного API.
Основні переваги CUDA в порівнянні з попередніми методами GPGPU випливають з того, що ця архітектура спроектована для ефективного використання неграфічних обчислень на GPU і використовує мову програмування C, не вимагаючи перенесення алгоритмів в зручний для концепції графічного конвеєра вид. CUDA пропонує новий шлях обчислень на GPU, який не використовує графічні API, що пропонує довільний доступ до пам'яті (scatter або gather). Така архітектура позбавлена недоліків GPGPU і використовує всі виконавчі блоки, а також розширює можливості за рахунок целочисленной математики та операцій бітового зсуву.
CUDA відкриває деякі апаратні можливості, недоступні з графічних API, такі як колективна пам'ять. Це пам'ять невеликого обсягу (16 кілобайт на мультипроцессор), до якої мають доступ блоки потоків. Вона дозволяє кешувати найбільш часто використовувані дані і може забезпечити більш високу швидкість, в порівнянні з використанням текстурних вибірок для цього завдання. Що, в свою чергу, знижує чутливість до пропускної спроможності паралельних алгоритмів у багатьох додатках. Наприклад, це корисно для лінійної алгебри, швидкого перетворення Фур'є і фільтрів обробки зображень.
Зручніше в CUDA і доступ до пам'яті. Програмний код в графічних API виводить дані у вигляді 32-х значень з плаваючою точкою одинарної точності (RGBA значення одночасно о восьмій render target) в заздалегідь зумовлені області, а CUDA підтримує scatter запис - необмежене число записів по будь-якою адресою. Такі переваги роблять можливим виконання на GPU деяких алгоритмів, які неможливо ефективно реалізувати за допомогою методів GPGPU, заснованих на графічних API.
Також, графічні API в обов'язковому порядку зберігають дані в структурах, що вимагає попередньої упаковки великих масивів в текстури, що ускладнює алгоритм і змушує використовувати спеціальну адресацію. А CUDA дозволяє читати дані по будь-якою адресою. Ще однією перевагою CUDA є оптимізований обмін даними між CPU і GPU. А для розробників, які бажають отримати доступ до низького рівня (наприклад, при написанні іншої мови програмування), CUDA пропонує можливість низькорівневого програмування на асемблері.
недоліки CUDA
Один з нечисленних недоліків CUDA - слабка переносимість. Ця архітектура працює тільки на відеочіпах цієї компанії, та ще й не на всіх, а починаючи з серії GeForce 8 і 9 та відповідних Quadro, ION і Tesla. NVIDIA наводить цифру в 90 мільйонів CUDA-сумісних відеочіпів.
альтернативи CUDA
Фреймворк для написання комп'ютерних програм, пов'язаних з паралельними обчисленнями на різних графічних і центральних процесорах. У фреймворк OpenCL входять мову програмування, який базується на стандарті C99, і інтерфейс програмування додатків (API). OpenCL забезпечує паралелізм на рівні інструкцій і на рівні даних і є реалізацією техніки GPGPU. OpenCL є повністю відкритим стандартом, його використання не обкладається ліцензійними відрахуваннями.
Мета OpenCL полягає в тому, щоб доповнити OpenGL і OpenAL, які є відкритими галузевими стандартами для тривимірної комп'ютерної графіки і звуку, користуючись можливостями GPU. OpenCL розробляється і підтримується некомерційним консорціумом Khronos Group, до якого входять багато великих компаній, включаючи Apple, AMD, Intel, nVidia, Sun Microsystems, Sony Computer Entertainment і інші.
CAL / IL (Compute Abstraction Layer / Intermediate Language)
ATI Stream Technology - це набір апаратних і програмних технологій, які дозволяють використовувати графічні процесори AMD, спільно з центральним процесором, для прискорення багатьох додатків (не тільки графічних).
Областями застосування ATI Stream є додатки, вимогливі до обчислювальному ресурсу, такі, як фінансовий аналіз або обробка сейсмічних даних. Використання потокового процесора дозволило збільшити швидкість деяких фінансових розрахунків в 55 разів у порівнянні з рішенням тієї ж завдання силами тільки центрального процесора.
Технологію ATI Stream в NVIDIA не вважають дуже сильним конкурентом. CUDA і Stream - це дві різні технології, які стоять на різних рівнях розвитку. Програмування для продуктів ATI набагато складніше - їхня мова скоріше нагадує асемблер. CUDA C, в свою чергу, набагато більш високорівнева мова. Писати на ньому зручніше і простіше. Для великих компаній-розробників це дуже важливо. Якщо говорити про продуктивність, то можна помітити, що її пікове значення в продуктах ATI вище, ніж в рішеннях NVIDIA. Але знову все зводиться до того, як цю потужність отримати.
DirectX11 (DirectCompute)
Інтерфейс програмування додатків, який входить до складу DirectX - набору API від Microsoft, який призначений для роботи на IBM PC-сумісних комп'ютерах під управлінням операційних систем сімейства Microsoft Windows. DirectCompute призначений для виконання обчислень загального призначення на графічних процесорах, будучи реалізацією концепції GPGPU. Спочатку DirectCompute був опублікований в складі DirectX 11, проте пізніше став доступний і для DirectX 10 і DirectX 10.1.
NVDIA CUDA в російській науковому середовищі.
Станом на грудень 2009 р, програмна модель CUDA викладається в 269 університетах світу. У Росії навчальні курси по CUDA читаються в Московському, Санкт-Петербурзькому, Казанському, Новосибірськом і Пермському державних університетах, Міжнародному університеті природи суспільства і людини "Дубна", Об'єднаному інституті ядерних досліджень, Московському інституті електронної техніки, Іванівському державному енергетичному університеті, БГТУ ім. В. Г. Шухова, МГТУ ім. Баумана, РХТУ ім. Менделєєва, Російському науковому центрі "Курчатовський інститут", Міжрегіональному суперкомпьютерном центрі РАН, Таганрозькій технологічному інституті (ТТІ ПФУ).
Використання GPU для обчислень за допомогою C ++ AMP
До сих пір в обговоренні прийомів паралельного програмування ми розглядали тільки ядра процесора. Ми придбали деякі навички розпаралелювання програм з кількох процесорів, синхронізації доступу до спільно використовуваних ресурсів і використання високошвидкісних примітивів синхронізації без застосування блокувань.
Однак, існує ще один спосіб розпаралелювання програм - графічні процесори (GPU), Що володіють великим числом ядер, ніж навіть високопродуктивні процесори. Ядра графічних процесорів прекрасно підходять для реалізації паралельних алгоритмів обробки даних, а велика їх кількість з лишком окупає незручності виконання програм на них. У цій статті ми познайомимося з одним із способів виконання програм на графічному процесорі, з використанням комплекту розширень мови C ++ під назвою C ++ AMP.
Розширення C ++ AMP засновані на мові C ++ і саме тому в даній статті будуть демонструватися приклади на мові C ++. Однак, при помірному використанні механізму взаємодій в. NET, ви зможете використовувати алгоритми C ++ AMP в своїх програмах для.NET. Але про це ми поговоримо в кінці статті.
Введення в C ++ AMP
По суті, графічний процесор є таким же процесором, як будь-які інші, але з особливим набором інструкцій, великою кількістю ядер і своїм протоколом доступу до пам'яті. Однак між сучасними графічними і звичайними процесорами існують великі відмінності, і їх розуміння є запорукою створення програм, ефективно використовують обчислювальні потужності графічного процесора.
Сучасні графічні процесори мають дуже маленьким набором інструкцій. Це має на увазі деякі обмеження: відсутність можливості виконання функцій, обмежений набір підтримуваних типів даних, відсутність бібліотечних функцій і інші. Деякі операції, такі як умовні переходи, можуть коштувати значно дорожче, ніж аналогічні операції, що виконуються на звичайних процесорах. Очевидно, що перенесення великих обсягів коду з процесора на графічний процесор при таких умовах вимагає значних зусиль.
Кількість ядер в середньому графічному процесор значно більше, ніж в середньому звичайному процесорі. Однак деякі завдання виявляються занадто маленькими або не дозволяють розбивати себе на досить велику кількість частин, щоб можна було отримати вигоду від застосування графічного процесора.
Підтримка синхронізації між ядрами графічного процесора, що виконують одну задачу, дуже мізерна, і повністю відсутня між ядрами графічного процесора, що виконують різні завдання. Ця обставина вимагає синхронізації графічного процесора зі звичайним процесором.
Відразу виникає питання, які завдання підходять для вирішення на графічному процесорі? Майте на увазі, що не всякий алгоритм підходить для виконання на графічному процесорі. Наприклад, графічні процесори не мають доступу до пристроїв введення / виводу, тому у вас не вийде підвищити продуктивність програми, яка витягає стрічки RSS з інтернету, за рахунок використання графічного процесора. Однак на графічний процесор можна перенести багато обчислювальні алгоритми і забезпечити масове їх розпаралелювання. Нижче наводиться кілька прикладів таких алгоритмів (цей список далеко не повний):
збільшення і зменшення різкості зображень, і інші перетворення;
швидке перетворення Фур'є;
транспонування і множення матриць;
сортування чисел;
інверсія хешу «в лоб».
Відмінним джерелом додаткових прикладів може служити блог Microsoft Native Concurrency, де наводяться фрагменти коду і пояснення до них для різних алгоритмів, реалізованих на C ++ AMP.
C ++ AMP - це фреймворк, що входить до складу Visual Studio 2012 дає розробникам на C ++ простий спосіб виконання обчислень на графічному процесорі і вимагає лише наявності драйвера DirectX 11. Корпорація Microsoft випустила C ++ AMP як відкриту специфікацію, яку може реалізувати будь-який виробник компіляторів.
Фреймворк C ++ AMP дозволяє виконувати код на графічних прискорювачах (accelerators), Є обчислювальними пристроями. За допомогою драйвера DirectX 11 фреймворк C ++ AMP динамічно виявляє все прискорювачі. До складу C ++ AMP входять також програмний емулятор прискорювача і емулятор на базі звичайного процесора, WARP, які служить запасним варіантом в системах без графічного процесора або з графічним процесором, але за відсутності драйвера DirectX 11, і використовує кілька ядер і інструкції SIMD.
А тепер приступимо до дослідження алгоритму, який легко можна распараллелить для виконання на графічному процесорі. Реалізація нижче приймає два вектора однакової довжини і обчислює поточечной результат. Складно уявити щось більш прямолінійний:
Void VectorAddExpPointwise (float * first, float * second, float * result, int length) (for (int i = 0; i< length; ++i) { result[i] = first[i] + exp(second[i]); } }
Щоб распараллелить цей алгоритм на звичайному процесорі, потрібно розбити діапазон ітерацій на кілька піддіапазонів і запустити по одному потоку виконання для кожного з них. Ми присвятили чимало часу в попередніх статтях саме такого способу розпаралелювання нашого першого прикладу пошуку простих чисел - ми бачили, як можна це зробити, створюючи потоки вручну, передаючи завдання пулу потоків і використовуючи Parallel.For і PLINQ для автоматичного розпаралелювання. Згадайте також, що при розпаралелювання схожих алгоритмів на звичайному процесорі ми особливо дбали, щоб не роздрібнити завдання на занадто дрібні завдання.
Для графічного процесора ці попередження не потрібні. Графічні процесори мають безліч ядер, що виконують потоки дуже швидко, а вартість перемикання контексту значно нижче, ніж в звичайних процесорах. Нижче наводиться фрагмент, який намагається використовувати функцію parallel_for_eachз фреймворка C ++ AMP:
#include
Тепер досліджуємо кожну частину коду окремо. Відразу зауважимо, що загальна форма головного циклу збереглася, але спочатку використовувався цикл for був замінений викликом функції parallel_for_each. Насправді, принцип перетворення циклу в виклик функції або методу для нас не новий - раніше вже демонструвався такий прийом із застосуванням методів Parallel.For () і Parallel.ForEach () з бібліотеки TPL.
Далі, вхідні дані (параметри first, second і result) обертаються екземплярами array_view. Клас array_view служить для обгортання даних, переданих графічного процесора (прискорювача). Його шаблонний параметр визначає тип даних і їх розмірність. Щоб виконати на графічному процесорі інструкції, які звертаються до даних, спочатку оброблюваних на звичайному процесорі, хтось або щось повинен подбати про копіювання даних в графічний процесор, тому що більшість сучасних графічних карт є окремими пристроями з власною пам'яттю. Цю задачу вирішують екземпляри array_view - вони забезпечують копіювання даних на вимогу і тільки коли вони дійсно необхідні.
Коли графічний процесор виконає завдання, дані копіюються назад. Створюючи екземпляри array_view з аргументом типу const, ми гарантуємо, що first і second будуть скопійовані в пам'ять графічного процесора, але не будуть копіюватися назад. Аналогічно, викликаючи discard_data (), Ми виключаємо копіювання result з пам'яті звичайного процесора в пам'ять прискорювача, але ці дані будуть копіюватися в зворотному напрямку.
Функція parallel_for_each приймає об'єкт extent, що визначає форму оброблюваних даних і функцію для застосування до кожного елементу в об'єкті extent. В наведеному вище прикладі ми використовували лямбда-функцію, підтримка яких з'явилася в стандарті ISO C ++ 2011 року (C ++ 11). Ключове слово restrict (amp) доручає компілятору перевірити можливість виконання тіла функції на графічному процесорі і відключає більшу частину синтаксису C ++, який не може бути скомпільовано в інструкції графічного процесора.
Параметр лямбда-функції, index<1>об'єкта, являє одновимірний індекс. Він повинен відповідати використовуваному об'єкту extent - якби ми оголосили об'єкт extent двовимірним (наприклад, визначивши форму вихідних даних у вигляді двовимірної матриці), індекс також мав би бути двовимірним. Приклад такої ситуації приводиться трохи нижче.
Нарешті, виклик методу synchronize ()в кінці методу VectorAddExpPointwise гарантує копіювання результатів обчислень з array_view avResult, вироблених графічним процесором, назад в масив result.
На цьому ми закінчуємо наше перше знайомство зі світом C ++ AMP, і тепер ми готові до більш докладним дослідженням, а так само до більш цікавим прикладів, що демонструють вигоди від використання паралельних обчислень на графічному процесорі. Сума векторів - не найвдаліший алгоритм і не найкращий кандидат для демонстрації використання графічного процесора через великі накладних витрат на копіювання даних. У наступному підрозділі будуть показані два більш цікаві приклади.
множення матриць
Перший «справжній» приклад, який ми розглянемо, - множення матриць. Для реалізації ми візьмемо простий кубічний алгоритм множення матриць, а не алгоритм Штрассена, що має час виконання, близьке до кубічного ~ O (n 2.807). Для двох матриць: матриці A розміром m x w і матриці B розміром w x n, наступна програма виконає їх множення і поверне результат - матрицю C розміром m x n:
Void MatrixMultiply (int * A, int m, int w, int * B, int n, int * C) (for (int i = 0; i< m; ++i) { for (int j = 0; j < n; ++j) { int sum = 0; for (int k = 0; k < w; ++k) { sum += A * B; } C = sum; } } }
Распараллеліть цю реалізацію можна декількома способами, і при бажанні распараллелить цей код для виконання на звичайному процесорі правильним вибором був би прийом розпаралелювання зовнішнього циклу. Однак графічний процесор має досить велику кількість ядер і распараллеліть тільки зовнішній цикл, ми не зможемо створити достатню кількість завдань, щоб завантажити роботою всі ядра. Тому має сенс распараллелить два зовнішніх циклу, залишивши внутрішній цикл недоторканим:
Void MatrixMultiply (int * A, int m, int w, int * B, int n, int * C) (array_view
Ця реалізація все ще близько нагадує послідовну реалізацію множення матриць і приклад додавання векторів, що приводилися вище, за винятком індексу, який тепер є двовимірним і доступний у внутрішньому циклі з застосуванням оператора. Наскільки ця версія швидше послідовною альтернативи, виконуваної на звичайному процесорі? Множення двох матриць (цілих чисел) розміром 1024 х 1024 послідовна версія на звичайному процесорі виконує в середньому 7350 мілісекунд, тоді як версія для графічного процесора - тримайтеся міцніше - 50 мілісекунд, в 147 разів швидше!
Моделювання руху частинок
Приклади розв'язання задач на графічному процесорі, представлені вище, мають дуже просту реалізацію внутрішнього циклу. Зрозуміло, що так буде не завжди. У блозі Native Concurrency, посилання на який вже наводилася вище, демонструється приклад моделювання гравітаційних взаємодій між частинками. Моделювання включає нескінченну кількість кроків; на кожному кроці обчислюються нові значення елементів вектора прискорень для кожної частки і потім визначаються їх нові координати. Тут распараллеливанию піддається вектор частинок - при досить великій кількості частинок (від декількох тисяч і вище) можна створити досить велику кількість завдань, щоб завантажити роботою всі ядра графічного процесора.
Основу алгоритму становить реалізація визначення результату взаємодій між двома частинками, як показано нижче, яку легко можна перенести на графічний процесор:
// тут float4 - це вектори з чотирма елементами, // представляють частинки, що беруть участь в операціях void bodybody_interaction (float4 & acceleration, const float4 p1, const float4 p2) restrict (amp) (float4 dist = p2 - p1; // w тут не використовується float absDist = dist.x * dist.x + dist.y * dist.y + dist.z * dist.z; float invDist = 1.0f / sqrt (absDist); float invDistCube = invDist * invDist * invDist; acceleration + = dist * PARTICLE_MASS * invDistCube;)
Вихідними даними на кожному кроці моделювання є масив з координатами і швидкостями руху частинок, а в результаті обчислень створюється новий масив з координатами і швидкостями частинок:
Struct particle (float4 position, velocity; // реалізації конструктора, конструктора копіювання і // оператора = з restrict (amp) опущені для економії місця); void simulation_step (array
Із залученням відповідного графічного інтерфейсу, моделювання може виявитися дуже цікавим. Повний приклад, представлений командою розробників C ++ AMP, можна знайти в блозі Native Concurrency. На моїй системі з процесором Intel Core i7 і відеокартою Geforce GT 740M, моделювання руху 10 000 частинок виконується зі швидкістю ~ 2.5 кадру в секунду (кроків в секунду) з використанням послідовної версії, що виконується на звичайному процесорі, і 160 кадрів в секунду з використанням оптимізованої версії, що виконується на графічному процесорі - величезне збільшення продуктивності.
Перш ніж завершити цей розділ, необхідно розповісти ще про одну важливу особливість фреймворка C ++ AMP, яка може ще більше підвищити продуктивність коду, що виконується на графічному процесорі. Графічні процесори підтримують програмований кеш даних(Часто званий пам'яттю (shared memory)). Значення, які у цьому кеші, спільно використовуються всіма потоками виконання в одній мозаїці (tile). Завдяки мозаїчної організації пам'яті, програми на основі фреймворку C ++ AMP можуть читати дані з пам'яті графічної карти в пам'ять, що розділяється мозаїки і потім звертатися до них з декількох потоків виконання без повторного вилучення цих даних з пам'яті графічної карти. Доступ до пам'яті, що мозаїки виконується приблизно в 10 разів швидше, ніж до пам'яті графічної карти. Іншими словами, у вас є причини продовжити читання.
Щоб забезпечити виконання мозаїчної версії паралельного циклу, методу parallel_for_each передається домен tiled_extent, Який ділить багатовимірний об'єкт extent на багатовимірні фрагменти мозаїки, і лямбда-параметр tiled_index, що визначає глобальний і локальний ідентифікатор потоку всередині мозаїки. Наприклад, матрицю 16x16 можна розділити на фрагменти мозаїки розміром 2x2 (як показано на малюнку нижче) і потім передати функції parallel_for_each:
Extent<2>matrix (16,16); tiled_extent<2,2>tiledMatrix = matrix.tile<2,2>(); parallel_for_each (tiledMatrix, [=] (tiled_index<2,2>idx) restrict (amp) (// ...));

Кожен з чотирьох потоків виконання, що належать одній і тій же мозаїці, можуть спільно використовувати дані, що зберігаються в блоці.
При виконанні операцій з матрицями, в ядрі графічного процесора, замість стандартного індексу index<2>, Як в прикладах вище, можна використовувати idx.global. Грамотне використання локальної мозаїчної пам'яті і локальних індексів може забезпечити істотний приріст продуктивності. Щоб оголосити мозаїчну пам'ять, що розділяється всіма потоками виконання в одній мозаїці, локальні змінні можна оголосити зі специфікатором tile_static.
На практиці часто використовується прийом оголошення розділяється пам'яті і ініціалізації окремих її блоків в різних потоках виконання:
Parallel_for_each (tiledMatrix, [=] (tiled_index<2,2>idx) restrict (amp) (// 32 байта спільно використовуються всіма потоками в блоці tile_static int local; // привласнити значення елементу для цього потоку виконання local = 42;));
Очевидно, що будь-які вигоди від використання розділяється пам'яті можна отримати тільки в разі синхронізації доступу до цієї пам'яті; тобто, потоки не повинні звертатися до пам'яті, поки вона не буде инициализирована одним з них. Синхронізація потоків в мозаїці виконується за допомогою об'єктів tile_barrier(Нагадує клас Barrier з бібліотеки TPL) - вони зможуть продовжити виконання тільки після виклику методу tile_barrier.Wait (), який поверне управління тільки коли всі потоки викличуть tile_barrier.Wait. наприклад:
Parallel_for_each (tiledMatrix, (tiled_index<2,2>idx) restrict (amp) (// 32 байта спільно використовуються всіма потоками в блоці tile_static int local; // привласнити значення елементу для цього потоку виконання local = 42; // idx.barrier - екземпляр tile_barrier idx.barrier.wait (); // Тепер цей потік може звертатися до масиву "local", // використовуючи індекси інших потоків виконання!));
Тепер саме час втілити отримані знання в конкретний приклад. Повернемося до реалізації множення матриць, виконаної без застосування мозаїчної організації пам'яті, і додамо в нього описувану оптимізацію. Припустимо, що розмір матриці кратний числу 256 - це дозволить нам працювати з блоками 16 х 16. Природа матриць допускає можливість поблочного їх множення, і ми можемо скористатися цією особливістю (фактично, розподіл матриць на блоки є типовою оптимізацією алгоритму множення матриць, що забезпечує більш ефективне використання кеша процесора).
Суть цього прийому зводиться до наступного. Щоб знайти C i, j (елемент в рядку i і в стовпці j в матриці результату), потрібно обчислити скалярний добуток між A i, * (i-й рядок першої матриці) і B *, j (j-й стовпець у другій матриці ). Однак, це еквівалентно обчисленню часткових скалярних творів рядки і стовпці з подальшим підсумовуванням результатів. Ми можемо використовувати цю обставину для перетворення алгоритму множення матриць в мозаїчну версію:
Void MatrixMultiply (int * A, int m, int w, int * B, int n, int * C) (array_view Суть описуваної оптимізації в тому, що кожен потік в мозаїці (для блоку 16 х 16 створюється 256 потоків) ініціалізує свій елемент в 16 х 16 локальних копіях фрагментів вихідних матриць A і B. Кожному потоку в мозаїці потрібно тільки один рядок і один стовпець з цих блоків, але все потоки разом будуть звертатися до кожного рядка і до кожному колонку по 16 разів. Такий підхід суттєво знижує кількість звернень до основної пам'яті. Щоб обчислити елемент (i, j) в матриці результату, алгоритму потрібна повна i-й рядок першої матриці і j-й стовпець другуматриці. Коли потоки мозаїці 16x16, представлені на діаграмі і k = 0, заштриховані області в першій і другій матрицях будуть прочитані в пам'ять, що розділяється. Потік виконання, що обчислює елемент (i, j) в матриці результату, вирахує часткове скалярний твір перших k елементів з i-го рядка і j-го стовпця вихідних матриць. В даному прикладі застосування мозаїчної організації забезпечує величезний приріст продуктивності. Мозаїчна версія множення матриць виконується набагато швидше простої версії і займає приблизно 17 мілісекунд (для тих же вихідних матриць розміром 1024 х 1024), що в 430 швидше версії, виконуваної на звичайному процесорі! Перш ніж закінчити обговорення фреймворка C ++ AMP, нам хотілося б згадати інструменти (в Visual Studio), наявні в розпорядженні розробників. Visual Studio 2012 пропонують відладчик для графічного процесора (GPU), що дозволяє встановлювати контрольні точки, досліджувати стек викликів, читати і змінювати значення локальних змінних (деякі прискорювачі підтримують налагодження для GPU безпосередньо; для інших Visual Studio використовує програмний симулятор), і профілювальник, що дає можливість оцінювати вигоди, одержувані додатком від розпаралелювання операцій із застосуванням графічного процесора. За додатковою інформацією про можливості налагодження в Visual Studio звертайтеся до статті «Покрокове керівництво. Налагодження програми C ++ AMP »на сайті MSDN. До сих пір в цій статті демонструвалися приклади тільки на мові C ++, проте, є кілька способів використовувати міць графічного процесора в керованих додатках. Один із способів - використовувати інструменти взаємодій, що дозволяють перекласти роботу з ядрами графічного процесора на низькорівневі компоненти C ++. Це рішення відмінно підходить для тих, хто бажає використовувати фреймворк C ++ AMP або має можливість використовувати вже готові компоненти C ++ AMP в керованих додатках. Інший спосіб - використовувати бібліотеку, безпосередньо працює з графічним процесором з керованого коду. В даний час існує декілька таких бібліотек. Наприклад, GPU.NET і CUDAfy.NET (обидві є комерційними пропозиціями). Нижче наводиться приклад зі сховищ GPU.NET GitHub, який демонструє реалізацію скалярного добутку двох векторів: Public static void MultiplyAddGpu (double a, double b, double c) (int ThreadId = BlockDimension.X * BlockIndex.X + ThreadIndex.X; int TotalThreads = BlockDimension.X * GridDimension.X; for (int ElementIdx = ThreadId; ElementIdx Я дотримуюся думки, що набагато простіше і ефективніше освоїти розширення мови (на основі C ++ AMP), ніж намагатися організовувати взаємодії на рівні бібліотек або вносити істотні зміни в мову IL. Отже, після того як ми розглянули можливості паралельного програмування в.NET і використанням GPU напевно ні у кого не залишилося сумнівів, що організація паралельних обчислень є важливим засобом підвищення продуктивності. У багатьох серверах і робочих станціях по всьому світу залишаються невикористовуваними безцінні обчислювальні потужності звичайних і графічних процесорів, тому що додатки просто не задіюють їх. Бібліотека Task Parallel Library дає нам унікальну можливість включити в роботу всі наявні ядра центрального процесора, хоча при цьому і доведеться вирішувати деякі цікаві проблеми синхронізації, надмірного дроблення завдань і нерівного розподілу роботи між потоками виконання. Фреймворк C ++ AMP та інші багатоцільові бібліотеки організації паралельних обчислень на графічному процесорі з успіхом можна використовувати для розпаралелювання обчислень між сотнями ядер графічного процесора. Нарешті, є, недосліджена раніше, можливість отримати приріст продуктивності від застосування хмарних технологій розподілених обчислень, що перетворилися останнім часом в один з основних напрямків розвитку інформаційних технологій. Ядер багато не буває ... Сучасні GPU - це монструозні спритні бестії, здатні пережовувати гігабайти даних. Однак людина хитрий і, як би не росли обчислювальні потужності, придумує завдання все складніше і складніше, так що приходить момент коли з сумом доводиться констатувати - потрібна оптимізацію 🙁 У даній статті описані основні поняття, для того щоб було легше орієнтуватися в теорії gpu-оптимізації і базові правила, для того щоб до цих понять, доводилося звертатися по-рідше. Причини по якій GPU ефективні для роботи з великими обсягами даних, що вимагають обробки: Пропускна здатність пам'яті (memory bandwidth)- це скільки інформації - біт або гігабайт - може може бути передано за одиницю часу секунду або процесорний такт. Одне із завдань оптимізації - задіяти по максимуму пропускну здатність - збільшити показники throughput(В ідеалі вона повинна бути дорівнює memory bandwidth). Для поліпшення використання пропускної здатності: Затримка (latency)- проміжок часу між моментами, коли контролер запросив конкретну осередок пам'яті і тим моментом, коли дані стали доступні процесору для виконання інструкцій. На саму затримку ми ніяк вплинути не можемо - ці обмеження присутні на апаратному рівні. Саме за рахунок цієї затримки процесор може одночасно обслуговувати кілька потоків - поки потік А запросив виділити йому пам'яті, потік Б може щось порахувати, а потік З чекати поки до нього прийдуть запитані дані. Як знизити затримку (latency) якщо використовується синхронізація: У високочолих розмовах про оптимізацію часто мелькає термін - gpu occupancyабо kernel occupancy- він відображає ефективність використання ресурсів-потужностей відеокарти. Окремо відзначу - якщо ви навіть і використовуєте всі ресурси - це аж ніяк не означає що ви використовуєте їх правильно. Обчислювальні потужності GPU - це сотні процесорів жадібних до обчислень, при створенні програми - ядра (kernel) - на плечі програміста лягати тягар розподілу навантаження на них. Помилка може привести до того, що велика частина цих дорогоцінних ресурсів може безцільно простоювати. Зараз я поясню чому. Почати доведеться здалеку. Нагадаю, що варп ( warp
в термінології NVidia, wavefront
- в термінології AMD) - набір потоків які одночасно виконують одну й ту ж саму функцію-Кернел на процесорі. Потоки, об'єднані програмістом в блоки розбиваються на варпа планувальником потоків (окремо для кожного мультипроцессора) - поки один варп працює, другий чекає обробки запитів до пам'яті і т.д. Якщо якісь з потоків варпа все ще виконують обчислення, а інші вже зробили все що могли - має місце бути неефективне використання обчислювального ресурсу - в народі іменується простоювання потужностей. Кожна точка синхронізації, кожне розгалуження логіки може породити таку ситуацію простою.
Максимальна дивергенція (розгалуження логіки виконання) залежить від розміру варпа. Для GPU від NVidia - це 32, для AMD - 64. Для того щоб знизити простої мультипроцессора під час виконання варпа: Для ефективного вирішення даного завдання має сенс розібратися - як же відбувається формування варпа (для випадку з кількома размерностями). Насправді порядок простий - в першу чергу по X, потім по Y і, в останню чергу, Z. ядро запускається з блоками розмірністю 64 × 16, потоки розбиваються по варпа в порядку X, Y, Z - тобто перші 64 елемента розбиваються на два варпа, потім другі і т.д. Ядро запускається з блоками розмірністю 16 × 64. У перший варп додаються перші і другі 16 елементів, в другій варп - треті і четверті і т.д. Як знижувати дивергенцію (пам'ятаєте - розгалуження - не завжди причина критичною втрати продуктивності) Як використовувати ресурси GPU по максимуму Ресурси GPU, на жаль, теж мають свої обмеження. І, строго кажучи, перед запуском функції-Кернел має сенс визначити ліміти і при розподілі навантаження ці ліміти врахувати. Чому це важливо? У відеокарт є обмеження на загальне число потоків, яке може виконувати один мультипроцессор, максимальне число потоків в одному блоці, максимальне число варпа на одному процесорі, обмеження на різні види пам'яті і т.п. Всю цю інформацію можна запросити як програмно, через відповідне API так і попередньо за допомогою утиліт з SDK. (Модулі deviceQuery для пристроїв NVidia, CLInfo - для відеокарт AMD). Загальна практика: При цьому слід враховувати що абсолютний мінімум - 3-4 варпа / вейфронта крутяться одночасно на кожному процесорі, мудрі гайди радять виходити з міркування - не менш семи вейфронатов. При цьому - не забувати обмеження по залізу! В голові всі ці деталі тримати швидко набридає, тому для розрахунок gpu-occupancy NVidia запропонувала несподіваний інструмент - ексельний (!) Калькулятор набитий макросами. Туди можна ввести інформацію по максимальному числу потоків для SM, число регістрів і розмір загальної (shared) пам'яті доступних на потоковому процесорі, і використовувані параметри запуску функцій - а він видає в процентах ефективність використання ресурсів (і ви рвете на голові волосся усвідомлюючи що щоб задіяти всі ядра вам не вистачає регістрів). інформація по використанню: GPU і операції з пам'яттю Відкрите оптимізовані для 128-бітних операцій з пам'яттю. Тобто в ідеалі - кожна маніпуляція з пам'яттю, в ідеалі, повинна змінювати за раз 4 чотирьох-байтних значення. Основна неприємність для програміста полягає в тому, що сучасні компілятори для GPU не вміють оптимізувати такі речі. Це доводиться робити прямо в коді функції і, в середньому, приносить частки-відсотка по приросту продуктивності. Набагато більший вплив на продуктивність має частота запитів до пам'яті. Проблема йде в наступному - кожен запит повертає у відповідь шматочок даних розміром кратний 128 бітам. А кожен потік використовує лише чверть його (в разі звичайної чотирьох-байтовой змінної). Коли суміжні потоки одночасно працюють з даними розташованими послідовно в осередках пам'яті - це знижує загальне число звернень до пам'яті. Називається це явище - об'єднані операції читання і запису ( coalesced access - good! both read and write) - і при вірній організації коду ( strided access to contiguous chunk of memory - bad!) Може відчутно поліпшити продуктивність. При організації свого ядра - пам'ятайте - суміжний доступ - в межах елементів одного рядка пам'яті, робота з елементами стовпчика - це вже не так ефективно. Хочете більше деталей? мені сподобалася ось ця pdf - або гуглити на предмет " memory coalescing techniques
“. Лідируючі позиції в номінації "вузьке місце" займає інша операція з пам'яттю - копію пам'яті хоста в ГПУ
. Копіювання відбувається не аби як, а з спеціально виділеної драйвером і системою області пам'яті: при запиті на копіювання даних - система спочатку копіює туди ці дані, а вже потім заливає їх в GPU. Швидкість транспортування даних обмежена пропускною здатністю шини PCI Express xN (де N число ліній передачі даних) через які сучасні відеокарти спілкуються з хостом. Однак, зайве копіювання повільної пам'яті на хості - це часом невиправдані витрати. Вихід - використовувати так звану pinned memory
- спеціальним чином позначену область пам'яті, так що операційна система не має можливості виконувати з нею будь-які операції (наприклад - вивантажити в свап / перемістити на свій розсуд і т.п.). Передача даних з хоста на відеокарту здійснюється без участі операційної системи - асинхронно, через DMA
(Direct memory access). І, на останок, ще трохи про пам'ять. Колективна пам'ять на мультипроцесорі зазвичай організована у вигляді банків пам'яті містять 32 бітні слова - дані. Число банків за доброю традицією варіюється від одного покоління GPU до іншого - 16/32 Якщо кожен потік звертається за даними в окремий банк - все добре. Інакше виходить кілька запитів на читання / запис до одного банку і ми отримуємо - конфлікт ( shared memory bank conflict). Такі конфліктні звернення серіалізуются і відповідно виконуються послідовно, а не паралельно. Якщо до одного банку звертаються все потоки - використовується "широкомовний" відповідь ( broadcast) І конфлікту немає. Існує кілька способів ефективно боротися з конфліктами доступу, мені сподобалося опис основних методик щодо позбавлення від конфліктів доступу до банків пам'яті
– . Як зробити математичні операції ще швидше? Пам'ятати що: Для розробників CUDA має сенс звернути пильну увагу на концепцію cuda stream,дозволяють запускати відразу декілька функцій-ядер на одному пристрої або поєднувати асинхронне копіювання даних з хоста на пристрій під час виконання функцій. OpenCL, поки, такого функціоналу не надає 🙁 Брухт для профілювання: NVifia Visual Profiler - цікава утилитка, аналізує ядра як CUDA так і OpenCL. P. S. Як більш розлогого керівництва по оптимізації, можу порекомендувати гуглити всілякі best practices guide
для OpenCL і CUDA. Розробнику слід навчитися ефективно використовувати графічний процесор пристрою (GPU), щоб програма не гальмувало і не виконувало зайву роботу. Якщо ваш додаток гальмує, значить частина або всі кадри оновлення екрану оновлюються більше ніж 16 мілісекунд. Щоб візуально побачити оновлення кадрів на екрані, можна на пристрої включити спеціальну опцію (Profile GPU Rendering). У вас з'явиться можливість швидко побачити, скільки часу займає отрисовка кадрів. Нагадаю, що потрібно вкладатися в 16 мілісекунд. Опція доступна на пристроях, починаючи з Android 4.1. На пристрої слід активувати режим розробника. На пристроях з версією 4.2 і вище режим за замовчуванням прихований. Для активації йде в налаштування | Про телефоніі сім раз клацаємо по рядку номер збірки. Після активації заходимо в Опції розробникаі знаходимо пункт Налаштувати параметри GPU візуалізації(Profile GPU rendering), який слід включити. У спливаючих вікні виберіть опцію На екрані у вигляді стовпчиків(On screen as bars). У цьому випадку графік буде виводитися поверх запущеного додатку. Ви можете протестувати не тільки свій додаток, а й інші. Запустіть будь-який додаток і починайте працювати з ним. Під час роботи в нижній частині екрана ви побачите оновлюваний графік. Горизонтальна вісь відповідає за минулий час. Вертикальна вісь показує час для кожного кадру в мілісекундах. При взаємодії з додатком, вертикальні смуги малюються на екрані, з'являючись зліва направо, показуючи продуктивність кадрів протягом якогось часу. Кожен такий стовпець представляє собою один кадр для відтворення екрану. Чим вище висота стовпчика, тим більше часу йде на отрисовку. Тонка зелена лінія є орієнтиром і відповідає 16 мілісекунд за кадр. Таким чином, вам потрібно прагнути до того, щоб при вивченні вашого застосування графік не вибивався за цю лінію. Розглянемо збільшену версію графіка. Зелена лінія відповідає за 16 мілісекунд. Щоб укластися в 60 кадрів в секунду, кожен стовпець графіка повинен малюватися нижче цієї лінії. В якихось моментах стовпець виявиться занадто великим і буде набагато вище зеленої лінії. Це означає гальмування програми. Кожен стовпець має блакитний, фіолетовий (Lollipop і вище), червоний і оранжевий кольори. Блакитний колір відповідає за час, що використовується на створення і оновлення View. Фіолетова частина являє собою час, витрачений на передачу ресурсів рендеринга потоку. Червоний колір є час для відтворення. Помаранчевий колір показує, скільки часу знадобилося процесору для очікування, коли GPU завершить свою роботу. Він і є джерелом проблем при великих величинах. Існують спеціальні методики для зменшення навантаження на графічний процесор. Інша настройка дозволяє дізнатися, як часто перемальовується один і той же ділянку екрана (тобто виконується зайва робота). Знову йдемо в Опції розробникаі знаходимо пункт Налагодити показник GPU overdraw(Debug GPU Overdraw), який слід включити. У спливаючих вікні виберіть опцію Показувати зони накладення(Show overdraw areas). Не лякайтесь! Нкоторие елементи на екрані змінять свій колір. Поверніться в будь-який додаток і поспостерігайте за його роботою. Колір підкаже проблемні ділянки вашого застосування. Якщо колір в додатку не змінився, значить все відмінно. Немає накладення одного кольору поверх іншого. Блакитний колір показує, що один шар малюється поверх нижнього шару. Добре. Зелений колір - перемальовується двічі. Потрібно задуматися про оптимізацію. Рожевий колір - перемальовується тричі. Все дуже погано. Червоний колір - перемальовується багато разів. Щось пішло не так. Ви можете самостійно перевірити свій додаток для пошуку проблемних місць. Створіть активність і помістіть на неї компонент TextView. Дайте кореневого елементу і текстової мітці якийсь фон в атрибуті android: background. У вас вийде наступне: спочатку ви зафарбували одним кольором самий нижній шар активності. Потім поверх неї малюється новий шар від TextView. До речі, на самому TextViewмалюється ще й текст. В якихось моментах накладення квітів не уникнути. Але уявіть собі, що ви таким же чином встановили фон для списку ListView, Який займає все площа активності. Система буде виконувати подвійну роботу, хоча нижній шар активності користувач ніколи не побачить. А якщо до того ж ви створите ще й власну розмітку для кожного елемента списку зі своїм фоном, то взагалі отримаєте перебір. Маленький рада. Помістіть після методу setContentView ()виклик методу, який прибере перірісовку екрану кольором теми. Це допоможе прибрати одне зайве накладення кольору: GetWindow (). SetBackgroundDrawable (null);
Альтернативи обчислень на графічному процесорі в.NET
Використання ресурсів GPU на повну - GPU Occupancy

http://docs.nvidia.com/cuda/cuda-c-best-practices-guide/#calculating-occupancyНалаштувати параметри GPU візуалізації
Налагодити показник GPU overdraw
