Останнім часом неодноразово виринає тема завантаження ресурсів. Коротко: «Я завантажую картинку з c:\work\image.gif, а коли запускаю програму з jar-файлу/на іншому комп'ютері - вона не вантажиться. Що робити?".
Тим часом нічого складного тут немає. Потрібно тільки розуміти принципи.
Насамперед, вантажити ресурси за абсолютною адресою на диску – безперспективне заняття. Думаю, самі чудово розумієте, чому – прибрали файл із диска, та «прощай ресурс». Все своє треба носити із собою.
Другий варіант, який я часто бачу – завантаження ресурсу з jar-файлу. Але тут дуже часто робиться одна помилка – ресурс намагаються вантажити через клас java.io.File. При цьому цей клас призначений тільки для роботи з файловими системами.
Хоча сама ідея правильна. Потрібний ресурс дійсно необхідно помістити у jar-файл. Потрібно тільки розуміти, як його звідти завантажити. Ось про це я й розповім.
Для завантаження ресурсу служать методи java.lang.Class.getResource(String), java.lang.Class.getResourceAsStream(Stri ng), java.lang.ClassLoader.getResource(String) та java.lang.ClassLoader.getResourceAsStrea m(String) . Методи Class-а делегують виклики ClassLoader-у.
GetResource(String) на ім'я ресурсу повертає java.net.URL , через який можна отримати цей ресурс. getResourceAsStream(String), як неважко здогадатися, повертає java.io.InputStream, через який ресурс можна прочитати.
Ім'я ресурсу є шлях до ресурсу. Є одна істотна тонкість, а саме як воно інтерпретується.
Ім'я може бути абсолютним та відносним. Зовнішня відмінність - абсолютне ім'я починається з символу "/". У першому випадку ресурс шукається щодо кореня classpath. Тобто. беруться всі шляхи та jar-файли, що входять до classpath, і ресурс шукається щодо сукупності цих точок. Якщо ж ім'я відносне – до нього спочатку приписується шлях, отриманий з пакета поточного класу. Далі пошук проводиться як у випадку абсолютного імені.
Найпростіше це зрозуміти на прикладах. Нехай у нас заданий classpath: c:\work\myproject\classes;c:\lib\lib.jar . Код прикладу знаходиться в класі ru.skipy.test.ResourceLoadingTest.
Приклад 1. Ми використовуємо конструкцію getClass().getResource("/images/logo.png") . Оскільки ім'я починається із символу "/" – воно вважається абсолютним. Пошук ресурсу відбувається так:
- До шляху з classpath c:\work\myproject\classes приписується ім'я ресурсу /images/logo.png , внаслідок чого шукається файл c:\work\myproject\classes\images\logo.pn g . Якщо файл знайдено, пошук припиняється. Інакше:
- У jar-файлі c:\lib\lib.jar шукається файл /images/logo.png, причому пошук ведеться від кореня jar-файлу.
- До шляху з classpath c:\work\myproject\classes приписується поточний пакет класу, де знаходиться код, - /ru/skipy/test , - і далі ім'я ресурсу res/data.txt , внаслідок чого шукається файл c:\work\ myproject\classes\ru\skipy\test\r es\data.txt . Якщо файл знайдено, пошук припиняється. Інакше:
- У jar-файлі c:\lib\lib.jar шукається файл /ru/skipy/test/res/data.txt (ім'я пакета поточного класу плюс ім'я ресурсу), причому пошук ведеться від кореня jar-файлу.
Ось тут можна завантажити повністю робочий приклад, що ілюструє обидва типи завантаження: . Ресурси – зображення та текст – розташовуються в окремій директорії, при складанні потрапляють у jar-файл та вантажаться один за абсолютним, інший за відносним ім'ям. Приклад збирається і запускається через ant, командою ant run він запускається з директорії складання build/classes/, командою ant run-jar - зі зібраного jar-файлу.
Ось десь так. Запитання? Коментарі?
к.е.н. Лавлінський Н. Є., технічний директор ТОВ "Метод Лаб"
Нещодавно опубліковано новий стандарт на технологію Preload (посилання). Основне завдання цієї специфікації було забезпечити можливість тонкого управління логікою завантаження ресурсів сторінки розробником.
Попередні стандарти
Ідея про управління завантаженням не нова. Раніше було розроблено кілька варіантів тегів linkз атрибутами subresource, prerenderі prefetch. Однак, вони працювали трохи інакше: за допомогою їх можна завантажувати елементи сторінок або цілі сторінки, які можуть знадобитися при подальшій навігації по сайту. Тобто, браузер надсилав такі запити з низьким пріоритетом і в останню чергу. Якщо потрібно підвищити пріоритет, то рішень не було.
Завантаження ресурсів із preload
Що дає нова специфікація? По-перше, тепер завантаження відбувається з уточненням, що завантажується. З зазначеного типу ресурсу браузером виставляється пріоритет завантаження. Наприклад:
link rel="preload" href="/js/script.js" as="script" >link rel = "preload" href = "/fonts/1.woff2" as= "font" type = "font/woff2" crossorigin>
По-друге, тип ресурсу ( as) дозволяє браузеру надіслати правильні заголовки, щоб сервер міг відправити контент з кращим варіантом стиснення (наприклад, надіслати WebP картинки, якщо браузер їх підтримує).
У другому прикладі ми завантажуємо файл шрифту, у своїй вказаний конкретний формат (WOFF2), який підтримується не всіма браузерами. Однак, поки підтримка механізму preload співпадає з підтримкою такого формату, проблем не виникає. Поточну підтримку механізму можна переглянути.
Прискорене завантаження шрифтів
Як приклад прискорення сайту з використанням preload, можна назвати завантаження глибоко закопаних ресурсів, наприклад, шрифтів. У звичайному процесі завантаження браузер повинен спочатку завантажити CSS-файл із зазначенням на шрифт, провести парсинг цього файлу і лише потім поставити запит на завантаження файлу шрифту.
Якщо ми вкажемо preload цього шрифту в коді HTML-сторінки, браузер відправить запит відразу після розбору HTML-документа, що може бути на кілька секунд раніше, ніж у звичайному випадку. А ми знаємо, що шрифти, що підключаються, є блокуючими елементами і затримують відображення шрифту на сторінці, тому завантажити їх потрібно якнайшвидше. Особливо гостро ця проблема стоїть при використанні HTTP/2, коли браузер відправляє відразу безліч запитів до сервера, внаслідок чого якісь картинки можуть заповнити смугу клієнта і завантаження важливих ресурсів буде відкладено.
Асинхронне завантаження CSS
CSS-файли завжди блокують рендеринг сторінки, тому всі CSS-ресурси, завантаження яких можна відкласти, можна завантажувати як звичайні файли та динамічно підключати до сторінки.
Робиться це так:
link rel="preload" as="style" href="async_style.css" onload="this.rel="stylesheet"" >Завантаження JS-коду без виконання
Також корисним може стати передзавантаження коду скрипта на JS, щоб виконати його пізніше.
Це можна зробити за допомогою наступного коду:
link rel="preload" as="script" href="async_script.js"onload = "var script = document.createElement("script"); script.src=this.href; document.body.appendChild(script);">Ми розглянули основні засоби використання механізму preload, але можливості на цьому не обмежуються, проводьте власні експерименти!
Як правило, багато вебмайстрів завантажують свої сайти на хост відразу після їх створення. У цьому вони переважно орієнтуються на правильність складання сенсу текстового змісту, ніж правильність внутрішнього коду сторінок.
Валідація сайту
Але є й інші фактори, які можуть впливати на позиції сайту. І до них належать, зокрема, і технічні чинники. Ну а до технічних належать і валідація сайту. То що це таке?
Якщо простими словами, то валідація сайту – це перевірка коду сайту на технічну відповідність та помилки. Ну наприклад, ви забули використовувати тег, що закриває /html. В останньому HTML5 візуально нічого не зміниться. Однак це помилка коду.
При написанні коду можливі інші помилки. І знову-таки, сучасна мова гіпер розмітки «стерпить» багато. Наприклад, «забуття» тега, що закриває /head. І знову ви не побачите різниці. Але вона є))
Насправді, при написанні сайту помилок може бути досить багато. І що гірше, деякі з цих помилок можуть проявитися і візуально. Ну може блоки попливуть, може вирівнювання, а може ще щось. Потенційні помилки, тисячі. І далеко не всі з них кидаються у вічі.
У чому небезпека?
Ну здавалося б, та й що тут такого? Так, треба сказати, що найчастіше такі помилки не видно. Точніше, невидимі людиною. Адже сторінки нашого сайту можуть відвідати не тільки люди, а й пошукові павуки, які повністю переглядають сайт. І кожну помилку, яку вони знаходять на сайті, вони передають на сервери пошукових систем, таких як Яндекс або Google.
А пошукові системи, у свою чергу, бачачи що на сайті багато помилок коду, цілком можуть зробити висновок про те, що сайт поганий. І значить, не підніматимуть його в пошуку. Ну а це вже означатиме, що прощай відвідувачі з пошуку.
Так, треба визнати, певна песимізація сайту через помилки валідації, це досить рідкісне явище. Але це цілком можливо, отже, над валідацією обов'язково потрібно працювати. А що для цього треба зробити? Зрозуміло, спочатку помилки треба знайти.
Але оскільки вручну це дуже трудомістка і ненадійна справа, то для пошуку помилок використовуються спеціальні сервіси, так звані «Валідатори».
Валідатор Markup Validation Service.
Цей сервіс перевіряє правильність кодів HTML та XHTML, які є основою більшої частини сторінок під час створення практично будь-якого сайту та визначають його внутрішню структуру. На цей сервіс валідатора можна потрапити, якщо пройти посилання http://validator.w3.org
Але тут є обов'язкова умова, яка також відноситься і до інших валідаторів: сайт, що перевіряється, або його сторінки, що перевіряються, повинні бути завантажені на хостинг. В іншому випадку, валідатор не знатиме адресу сайту і не зможе нічого перевірити. Ось зараз можна вже розглянути, як працювати на цьому валідаторі.
Після заходу на сторінку цього сервісу відобразиться вся його функціональна картинка. Але більшість зображеного і написаного до основної перевірки не відноситься і всю свою увагу треба звернути тільки на вікно введення адреси сторінки, що перевіряється:
Саме з нього і треба починати.
Взагалі-то, перевірка валідації сайту надзвичайно проста, як і весь наш тлінний світ: в адресному вікні сервісу треба написати адресу сайту, тобто. його URL і потім натиснути "Check". Після такої простої дії, валідатор «попихкає» кілька секунд і видасть таке:
Це означає, що жодних помилок у коді сторінки немає і Ви можете бути спокійні.
Але також може бути такий небажаний варіант:

Це вже гірше і означає, що у внутрішньому коді сторінки, що перевіряється, є якісь помилки. Однак це зовсім не смертельно: просто треба прокрутити сторінку нижче і там докладно будуть написані всі знайдені помилки в процесі перевірки.

Крім того, валідатор не лише перерахує знайдені помилки, але й точно покаже, на якому рядку внутрішнього коду ці помилки розташовані. Тож довго їх шукати не доведеться. Тут, нічого не перебільшуючи, можна твердо сказати, що цей валідор працює чудово.
Але це ще не все: валідатор не тільки вказує розташування виявленої помилки коду, але й дає досить повні рекомендації, яким чином можна усунути ці помилки. Звичайно, для цього не треба лінуватися та уважно прочитати все написане.
Як короткий і узагальнений висновок, можна сказати наступне:
- Цей сервіс валідатора працює чудово і може дуже швидко провести перевірку сайту.
- Ну і невеликий, але дуже приємний додаток: валідація сайту проводитися безкоштовно.
- Наразі можна перейти до наступного етапу: це перевірка коду CSS.
Валідатор CSS Validation Service
Загалом це друга функція описаного вище сервісу, але вона «заточена» не для перевірки коду HTML і XHTML, а саме для перевірки правильності коду стилю CSS, розташованого на зовнішній таблиці. Щоб потрапити на сторінку сервісу, треба пройти за посиланням http://jigsaw.w3.org/css-validator .
До речі, тут варто відзначити щось приємне: перевірка на цьому сервісі є абсолютно безкоштовною. Отже, не треба витягувати гроші зі свого гаманця — нехай вони лежать до потрібного моменту. Однак перейдемо до методики роботи на цьому другому сервісі.
Загалом вся робота на валідаторе CSS абсолютно ідентична перевірці на чистоту коду. Тому наводити окрему картинку адресного рядка валідатора немає необхідності. Просто трохи нижче коротко розглянемо безпосередньо порядок перевірки і все.
Для цього треба в адресному рядку записати URL таблиці CSS типу «http://мой сайт/style.css» і після цього натиснути кнопку з російським написом «Перевірити». Відповідно, цей валідатор теж кілька секунд «попихкає» і видасть результат:
Це означає, що таблиця CSS написана правильно і жодних помилок у ній не виявлено.
І тут також є приємна несподіванка: якщо прокрутити сторінку дещо нижче, то там буде написано оптимізований код для Вашої таблиці CSS, з якого прибрано всі зайві написи і всі теги коду будуть розставлені в тій послідовності, яка відповідає оптимальним вимогам всіх пошукових систем. Залишається лише скопіювати цей ідеальний зразок коду та вставити його в таблицю CSS.
Цілком можливо, що трапиться і такий варіант:

Це означає, що виявлено якісь помилки у коді CSS, але лякатися цього не варто. Відразу внизу під цим червоним рядком валідатор точно вкаже, який тег написаний неправильно. Залишається тільки в таблиці стилю знайти ці теги та зробити необхідні виправлення.

І звичайно, після цього завантажити виправлену таблицю стилю на хост і за наявності зеленого рядка можна із задоволенням скопіювати оптимізований код стилю CSS. Цілком зрозуміло, що потім краще поміняти старий код на новий та оптимізований.
Короткий резюме.
Вище були розглянуті дві основні і обов'язкові перевірки валідації сайту. Без цих перевірок навіть не варто відкривати індексацію для пошукових систем у robots.txt. Інакше, сайт може бути проігнорований для індексації пошуковими машинами і буде вважатися несправним з відповідними санкціями.
Щоб цього не сталося, треба витратити лише кілька хвилин, щоб бути абсолютно спокійним та повністю впевненим у технічному стані свого сайту та всіх його сторінок. Звичайно, необхідно зробити додаткові перевірки посилань і анкорів, видимості сайту на мобільних пристроях і параметри інших кодів. Тільки тоді сайт можна вважати готовим для його повного функціонування та для вдалого та швидкого просування у ТОП.
Заздалегідь хочеться сказати, що всі інші перевірки проходять так швидко і просто, як і розглянуті вище — треба тільки уважно прочитати порядок роботи з валідатором.
Додано 19.04.2018р.
Поширені помилки валідності під час перевірки html коду
Вирішив доповнити статтю помилками HTML-коду, які часто зустрічаються на сайтах. У всякому разі, у мене їх було багато)). Самі помилки валідатор підсвічує жовтим кольором.
1) Error: Character reference was not terminated by a semicolon.

Помилка: символ не був перерваний крапкою з комою відповідно треба додати.
2) Warning: Section lacks heading. Consider using h2-h6 elements до add identifying headings до all sections.
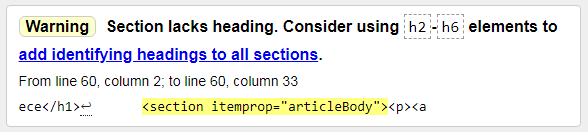
Попередження: Розділ не має заголовка. Розгляньте можливість використання елементів h2-h6 для додавання ідентифікуючих заголовків до всіх розділів. Тут все зрозуміло, треба додати бодай один підзаголовок. Це навіть не помилка, а рекомендація.
3) Error: Element noindex не дозволяється як дитину елемента в цьому контексті.

Помилка: елемент noindex не дозволений як дочірній елемент p елемента в цьому контексті. (Придушення подальших помилок із цього піддерева.)
Рішення просте, треба закоментувати тег ноіндекс, вигляд буде таким:
4) Error: The center element is obsolete.
Помилка: тег «center» застарів — треба замінити, якщо мова про img можна використовувати атрибут align. Якщо щось інше центрували, замінити на div.
5) An img element must have an alt atribut, except under certain

Помилка: Елемент img повинен мати атрибут alt - тут все зрозуміло, треба додати атрибут альт, навіть якщо він буде незаповнений, помилка піде.
6) The width attribute on the td element is obsolete. Use CSS instead.
Помилка: Атрибут width на елементі td застарів

7) Type atribut is unnecessary for javascript resources

Помилка: атрибут type не потрібний для ресурсів javascript. Рішення просто видаляємо все зайве і залишаємо лише тег "script".
8) The align attribute on the img element is obsolete.

Помилка: Атрибут align для img елемент застарілий. Зробіть вирівнювання зображень дивами.
Консорціум Всесвітньої павутини (World Wide Web Consortium, W3C) рекомендував технологію CSS (Cascading Style Sheets) у 1996 році. З того часу веб-розробники використовують каскадні таблиці стилів для створення унікального оформлення веб-сайтів.
Двадцять років тому розробники грали з параметрами шрифтів, атрибутами тексту та кольорами елементів сторінки. Зараз у ході анімації, тіні, градієнти, згладжування та багато інших просунутих речей.
Встановіть розширення Web Developer для Chrome або доповнення Disable CSS для Firefox, щоб помилуватися улюбленими сайтами без каскадних таблиць стилів.
Зміни будуть разючими, хоч і не завжди. Наприклад, новинний агрегатор Drudge Report майже не зміниться: він простий як двічі по два. Проте щомісяця ресурс переглядають понад 150 мільйонів разів.
Де навчитися тонкощам CSS

Будемо послідовні та почнемо з міцної теоретичної бази. За нею звернемося до Влада Мержевича, автора книг та веб-розробника, який підтримує кілька якісних ресурсів про верстку та стилізацію веб-сторінок.
На ви знайдете зрозумілий самовчитель та відповіді на популярні питання про каскадні таблиці стилів. Тут же представлені учбові статті про актуальну третю специфікацію CSS.

Пропонує алфавітний довідник із CSS. Кожна властивість має короткий опис, синтаксис та живий приклад. Не соромтеся ставити запитання – автори проекту виходять на зв'язок та охоче обговорюють деталі.

На додачу до російськомовних самовчителів додамо зарубіжні сайти. Деяким студентам за їх допомогою простіше вникати у професію та приймати її термінологію. Тому вся увага на . На сайті немає нічого зайвого: властивості CSS, пояснення та дія. З приємних дрібниць відзначимо швидкий пошук та копіювання якості в буфер обміну по клацанню миші.

Навчання - справа довга і часом нудна. Непогано знайти мотивацію, щоб вона допомагала у важкі хвилини. Надихатимемося в інших веб-дизайнерів, а точніше на сайті. Тут щодня представляють якісний проект, який є взірцем того, чого варто прагнути. Багато хто з переможців справді дивує. Не забувайте заглядати і голосувати за номінантів, що сподобалися.

Заручившись знаннями і маяком, настав час випробувати свої сили у справі. І щоб довго не вибирати дорогу, направимо вас на сторінку. На ній викладено постійний HTML-файл, якому користувачі з усього світу намагаються надати неординарний дизайн за допомогою каскадних таблиць стилів.
Завантажте стандартний HTML, додайте своє оформлення і відправте все це назад. Можливо, ваш підхід виявиться найкращим. До речі, можна скачати чужий варіант і подивитися, як він реалізований.

Зрозуміло, що вам захочеться застосувати щось таке, що приверне загальну увагу. Не знаємо, чи є таке, але десятки і сотні цікавих прийомів там точно завалялися.
Завантажити код не вийде. Вам доведеться залізти в меню розробників – така політика місцевої партії. При цьому переважну більшість CSS-стилів можна використовувати без дозволу автора.

Навіщо нам чуже, якщо у самих руки прямо зростають? Чи так воно насправді покаже. Крім базової перевірки синтаксису CSS, веб-сервіс виконує перевірку на відповідність правилам, що впливають на швидкість завантаження сторінок. На виході отримуємо добрий, милий для браузерів CSS-код.
А які ресурси про каскадні таблиці стилів можете порадити ви?
Усі HTML посилання поділяються на зовнішні та внутрішні. Зовнішні посилання – це посилання, що ведуть з одного сайту на інший сайт або файл, розташований на іншому сайті. Внутрішні посилання- це посилання, що посилаються з однієї сторінки сайту на іншу сторінку цього сайту або на розділи цієї ж сторінки.
Всі зовнішні посилання в атрибуті href тега містять абсолютний шлях до документа, на який вони посилаються. Внутрішні посилання, своєю чергою, можуть містити як абсолютний шлях, і відносний (у разі це залежить від ваших особистих переваг).
Всі посилання можна також умовно поділити на відносні та абсолютні. Відносні посилання- це посилання, що містять відносні шляхи, відносні посилання можуть бути тільки внутрішніми. Абсолютні посилання- це посилання, що містять абсолютні шляхи, абсолютні посилання можуть бути як зовнішніми, так і внутрішніми.
Відносний шлях
Відносний шляхозначає, що вказівка шляху на потрібний файл або сторінку вашого сайту починається щодо каталогу, в якому розташована сторінка з посиланням, або щодо кореневого каталогу сайту. Розглянемо частини, у тому числі може складатися відносний шлях:
| Частини колії | Опис | Приклади значень |
|---|---|---|
| ім'я файлу | Якщо в якості значення атрибута вказати тільки ім'я файлу, це означає, що потрібний файл знаходиться в тій же папці, де сторінка з посиланням. | "page.html" |
| каталог/ | Якщо файл, до якого потрібно вказати шлях, розташований у дочірньому каталозі щодо файлу з посиланням, це означає, що нам треба спуститися на один рівень донизу (у дочірню папку поточного каталогу), у цьому випадку шлях починається із вказівки імені дочірнього каталогу, після його імені вказується прямий слеш " / ", він служить поділу частин шляху, після нього вказується ім'я потрібного нам файла. Примітка: можна опуститися рівно на стільки папок вниз, скільки ви створили. Наприклад, якщо ви створили папку на 10 рівнів нижче за кореневу, то можете вказати шлях, який приведе вас вниз на 10 папок. Однак, якщо у вас так багато рівнів, це, швидше за все, означає, що організація вашого сайту надто складна. |
"каталог/page.html" "каталог1/каталог2/page.html" |
| ../ | Якщо потрібно вказати, що файл, на який ви посилаєтеся, знаходиться в батьківській папці, використовуйте символи (дві точки), вони означають піднятися на один рівень вгору (до батьківської папки поточного каталогу). Далі ми вказуємо прямий слеш "/", щоб поділити частини шляху, і пишемо ім'я нашого файлу. Примітка: символи.. можна використовувати скільки завгодно разів поспіль, використовуючи їх, ви піднімаєтеся щоразу одну папку вгору. Однак, підніматися нагору можна доти, доки не прийдете в кореневу папку свого сайту. Вище цієї папки піднятися не можна. |
" ../page.html " " ../../page.html " " ../../../кат1/кат2/page.html " - піднімаємося з поточної папки на три каталоги вище і вже з нього спускаємося на два рівні нижче до потрібного файлу |
| / | Відносний шлях не обов'язково завжди повинен починатися щодо поточного розташування сторінки з посиланням, він також може починатися щодо кореневого каталогу сайту. Наприклад, якщо потрібний файл знаходиться в кореневому каталозі, шлях може починатися з символу "/", після якого треба лише вказати ім'я потрібного файлу, який розташований у кореневому каталозі. Примітка: коли символ " / " вказується першим, це означає початок шляху кореневого каталогу. | /page.html /кат1/кат2/car.png |
Абсолютний шлях
Абсолютний шлях зазвичай застосовується для вказівки шляху до файлу, розташованого на іншому мережному ресурсі. Він являє собою повну URL-адресу до файлу або сторінки. Насамперед на адресу вказується протокол, що використовується, після якого йде назва домену (ім'я сайту). Наприклад: http://www.пример.ру – так виглядає абсолютний шлях до конкретного веб-сайту. http:// - це протокол передачі, а www.пример.ру - ім'я сайту (домен).
Абсолютний шлях можна використати і на власному сайті. Однак усередині сайту рекомендується використовувати як значення посилань відносний шлях.
Тепер давайте розглянемо, що таке URL-Адреса. Кожна веб-сторінка в мережі Інтернет має свою власну унікальну адресу, ось вона якраз і називається URL. Абревіатура URLрозшифровується як U niform R esource L ocator (уніфікована адреса ресурсу), URL - це визначник місцезнаходження ресурсу. Цей спосіб запису адреси стандартизовано в Інтернеті.