Vyhľadajte na stránke
Hľadať

Často sa objavuje otázka: prečo v Adobe Media Encoder CC nie je akcelerácia GPU?

A skutočnosť, že Adobe Media Encoder je GPU akcelerovaná wiki, sme vysvetlili a tiež nuansy tejto wiki.

Je tiež zrejmé, že podpora GPU bola pridaná do Adobe Media Encoder CC zrýchleným tempom.
Táto myšlienka vychádza zo skutočnosti, že hlavný program Adobe Premiere Pro CC je teraz možné spustiť bez registrovanej a odporúčanej grafickej karty a na aktiváciu enginu GPU v aplikácii Adobe Media Encoder CC musí byť grafická karta jasne zaregistrovaná v dokumentoch: cuda_supported_cards alebo opencl _supported_cards. Čo sa týka čipsetov nVidia, všetko je jasné, stačí vziať názov čipsetu a zadať ho do dokumentu cuda_supported_cards. Ak si vyberiete grafickú kartu AMD, musíte zaregistrovať nie názov čipovej sady, ale kódové označenie jadra.
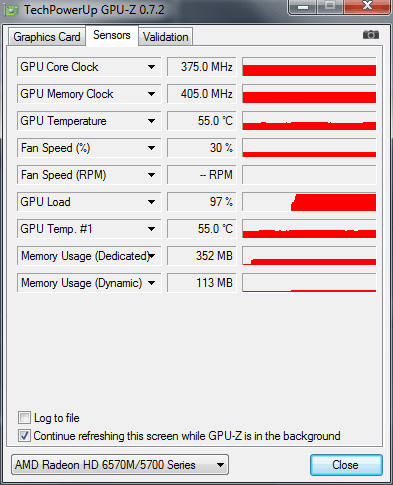
Pozrime sa teda, ako povoliť GPU engine v Adobe Media Encoder CC na notebooku ASUS N71JQ s diskrétnou grafikou ATI Mobility Radeon HD 5730.


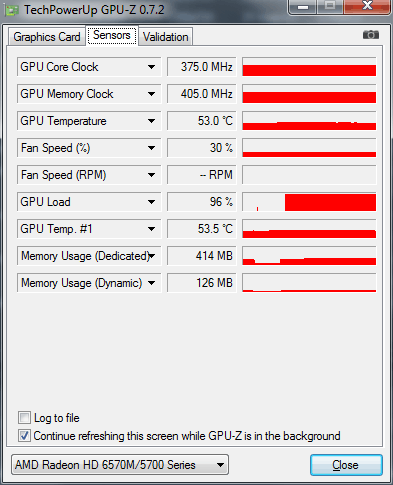
Technické údaje grafického adaptéra ATI Mobility Radeon HD 5730 sa zobrazujú pomocou pomôcky GPU-Z:


Spustite Adobe Premiere Pro CC a zapnite motor: Mercury Playback Engine GPU Acceleration (OpenCL). Tri videá DSLR na časovej osi, jedno nad jedným, dve pod nimi, vytvárajú efekt obrazu v obraze..

Ctrl + M, vyberte predvoľbu Mpeg2-DVD, odstráňte tmavohnedú zo strán pomocou ďalšej možnosti Scale To Fill.

Táto myšlienka vychádza zo skutočnosti, že hlavný program Adobe Premiere Pro CC je teraz možné spustiť bez registrovanej a odporúčanej grafickej karty a na aktiváciu enginu GPU v aplikácii Adobe Media Encoder CC musí byť grafická karta jasne zaregistrovaná v dokumentoch: cuda_supported_cards alebo opencl _supported_cards. Súčasťou je aj pokročilý nástroj na testy bez GPU: MRQ (Use Maximum Render Quality)..

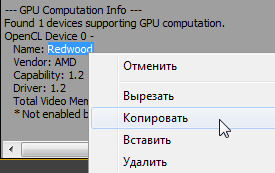
Teraz zapneme GPU engine v Adobe Media Encoder CC, spustíme program Adobe Premiere Pro CC, stlačíme kombináciu klávesov: Ctrl + F12, vyberieme Console> Console View a do poľa Command zadáme GPUSniffer, stlačte Enter.

Názvy sú viditeľné a skopírované v informáciách o výpočte GPU.
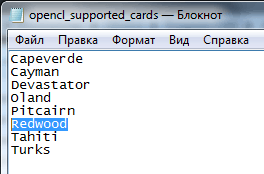
V adresári programu Adobe Premiere Pro CC otvorte dokument opencl_supported_cards a zadajte kódový názov čipovej sady v abecednom poradí, Ctrl + S.
Kliknite na tlačidlo: Queue a GPU urýchli spracovanie projektu Adobe Premiere Pro CC do Adobe Media Encoder CC.
Podsumkov hodina: Čo sa týka čipsetov nVidia, všetko je jasné, stačí vziať názov čipsetu a zadať ho do dokumentu cuda_supported_cards..

Pripojíme notebook k elektrickej zásuvke a zopakujeme výsledky testov.

Fronta, políčko MRQ nie je začiarknuté, bez zapnutého motora sa množstvo pamäte RAM trochu zvýšilo:

Podsumkov hodina: Frekvencia procesora: 1,6 GHz pri práci zo zásuvky a v režime: Vysoká produktivita..

46 sekúnd
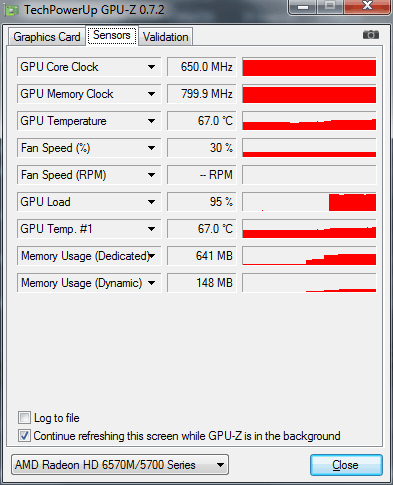
Motor je zapnutý: Mercury Playback Engine GPU Acceleration (OpenCL), ako je vidieť z videa, grafická karta notebooku beží na svojich základných frekvenciách, využitie GPU v Adobe Media Encoder CC dosahuje 95 %. Pidsumkov hodina prorakhunku, znížená z 1 hvilini 55 sekúnd , až.

1 hodina a 5 sekúnd
* Vizualizácia v aplikácii Adobe Media Encoder CC sa teraz spolieha na jednotku grafického spracovania (GPU).
Podporované sú štandardy CUDA a OpenCL.
V Adobe Media Encoder CC sa GPU engine používa na nadchádzajúce procesy vykresľovania:
- Zmeňte jasnosť (z vysokej na štandardnú a celú cestu).
- Filter časového kódu.
- Prepracovanie pixelového formátu.
- Prekladanie.
Technológia CUDA (Compute Unified Device Architecture) je hardvérovo-softvérová architektúra, ktorá umožňuje výpočtové spracovanie grafických procesorov NVIDIA, ktorá podporuje technológiu GPGPU (pokročilé výpočty).
Architektúra CUDA sa prvýkrát objavila na trhu s vydaním čipu NVIDIA ôsmej generácie - G80 a je prítomná vo všetkých pripravovaných sériách grafických čipov, ktoré sú vyvinuté v rodičkách problémových GeForce, ION, Quadro a Tesla.
CUDA SDK umožňuje programom implementovať C algoritmy bežiace na grafických procesoroch NVIDIA v špeciálnom zjednodušenom dialekte programovania v C a zahrnúť špeciálne funkcie do textu programov C.
CUDA dáva vývojárovi možnosť podľa vlastného uváženia organizovať prístup k sade inštrukcií grafického procesora a spravovať jeho pamäť a organizovať paralelné výpočty na novej platforme.
História
V roku 2003 súperili Intel a AMD v súťaži o najvýkonnejší procesor.
Dôvod, prečo sa výrobcovia GPU s týmto problémom nestretli, je celkom jednoduchý: centrálne procesory sú rozdelené, aby sa maximalizovala produktivita na inštrukcie, ktoré spracovávajú rôzne dáta (čísla aj čísla), vibrujú konkávny prístup k pamäti atď , sa vývojári snažia zabezpečiť väčšiu paralelnosť inštrukcií – aby mohli písať paralelne väčší počet inštrukcií.
Napríklad v Pentiu sa objavila superskalárna vikonika, pretože so správnymi mysľami bolo možné vikonovať dve inštrukcie za cyklus hodín.

Pentium Pro bolo aktualizované krok za krokom o nové inštrukcie, ktoré nám umožnili optimalizovať činnosť výpočtových jednotiek.
Problém spočíva v tom, že paralelný tok sekvenčného toku inštrukcií má zjavné obmedzenia, takže posun v počte výpočtových blokov nevyhráva, pretože väčšinu času budú stále nečinné.
Obsluha GPU je pozoruhodne jednoduchá.
Najpopulárnejší BrookGPU je kompilátor pre Brookove streamovanie filmového programovania, výtvory pre negrafické výpočty na GPU.
Predtým sa objavili vývojári, ktorí chceli preskúmať možnosti video čipov na výpočty, a vybrali si jedno z dvoch rozšírení API: Direct3D alebo OpenGL.
To vážne narušilo stagnáciu GPU a dokonca aj v 3D grafike sa používajú shadery a textúry, čo znamená, že paralelné programovanie nevyžaduje použitie vlákien a jadier.
Brook pomohol zmierniť ich problémy.
Tieto prúdy boli rozšírené na jazyk C, vyvinutý na Stanfordskej univerzite, s použitím triviálneho API od programátorov a prezentujúcich video vo forme paralelného procesora.
Kompilátor vytvorí súbor .br s kódom C++ a príponami, skompiluje kód, prepojí sa s knižnicou s podporou DirectX, OpenGL alebo x86.
Vznik Brooka pritiahol záujem spoločností NVIDIA a ATI a ďalej, čím sa otvoril úplne nový sektor – paralelné výpočty založené na video čipoch.
Potom sa členovia projektu Brook presunuli do vývojového tímu NVIDIA, aby predstavili softvérovú a hardvérovú stratégiu pre paralelné výpočty, čím sa otvorila nová časť trhu.
A hlavnou výhodou iniciatívy NVIDIA je, že vývojári jasne poznajú všetky možnosti svojich GPU do detailov a nie je potrebné používať iné grafické API a platiť za hardvér Bez problémov s pečeňou môžete získať pomoc bez pomoci od vodič.
Výsledkom snaženia tohto tímu bola NVIDIA CUDA.

Zoznam hlavných doplnkov, ktoré prispievajú k výpočtom na GPU: analýza a spracovanie obrazov a signálov, simulácia fyziky, výpočtová matematika, výpočtová biológia, finančný rozvoj, databázy, dynamika plynov a riek, kryptografia, adaptívna výmenná terapia, astronómia , spracovanie zvuku, bioinformatika, biologické simulácie, informatika, dolovanie dát, digitálne kino a televízia, elektromagnetické simulácie, geoinformačné systémy, vojenská stagnácia, urbanizmus, molekulárna dynamika, magnetická rezonancia (MRI), neuroprieskumy, oceánografický výskum, častice fyziky, simulácia príjmu proteínových molekúl, kvantová chémia, výmenný prenos, zobrazovanie, radary, hydrodynamické modelovanie (simulácia nádrží), kusová inteligencia, analýza satelitných dát, seizmický prieskum, rádioterapia, ultrazvuk, videokonferencie.
Výhody a výmeny CUDA
Z pohľadu programátora je grafický dopravník súborom fáz spracovania.

Geometrický blok generuje trikutánne prvky a rasterizačný blok generuje pixely, ktoré sú zobrazené na monitore.
Tradičný programovací model GPGPU vyzerá takto:
Softvérová a hardvérová architektúra pre výpočty na GPU od NVIDIA sa vyvíja z najnovších modelov GPGPU v tom, že vám umožňuje písať programy pre GPU v rovnakom jazyku so štandardnou syntaxou, indikátory a potreba Inimums sú rozšírené o prístup k videu. výpočtových zdrojov.
CUDA neobsahuje grafické rozhrania API a obsahuje niekoľko funkcií navrhnutých špeciálne na výpočet legálnych funkcií.
Výhody CUDA oproti tradičnému prístupu k výpočtu GPGPU
CUDA poskytne prístup až k 16 KB pamäťovým vláknam na multiprocesor, ktoré možno použiť na organizáciu vyrovnávacej pamäte so širokou šírkou pásma v súlade s načítaním textúr;
Efektívnejší prenos dát medzi systémom a video pamäťou;
Nie sú potrebné grafické API s réžiou a réžiou;
Lineárne adresovanie pamäte, zhromažďovanie a rozptyl, schopnosť zapisovať na viacero adries;
Hardvérová podpora celočíselných a bitových operácií.
Základné rozhrania CUDA:
Dostupnosť podpory rekurzie pre zreťazené funkcie;
Minimálna šírka bloku v 32 prúdoch;
Architektúra CUDA je uzavretá, čo má na starosti NVIDIA.
Slabé miesta programovania pomocou pokročilých metód GPGPU sú tie, že tieto metódy nevyberajú bloky shaderov vertexov v pokročilých nezjednotených architektúrach, údaje sa ukladajú do štruktúr a zobrazujú sa v skrínovanej vyrovnávacej pamäti a algoritmy bohato vyberajú jednotky pixel shader.
CUDA odhaľuje možnosti hardvéru, ktoré nie sú dostupné z grafického rozhrania API, ako je napríklad kolektívna pamäť.
Pamäť je malá (16 kilobajtov na multiprocesor), ku ktorej možno pristupovať pomocou blokov vlákien.
To vám umožňuje extrahovať najčastejšie spracovávané údaje a môže poskytnúť väčšiu plynulosť v závislosti od rôznych výberov textúr pre túto úlohu.
Čo zase znižuje citlivosť na priepustnosť paralelných algoritmov v mnohých aplikáciách.
Je to užitočné napríklad pre lineárnu algebru, Fourierovu hladkú transformáciu a filtre na spracovanie obrazu.
Lepší prístup k pamäti v CUDA.
Programový kód v grafickom rozhraní API zobrazuje údaje vo forme 32 s jednoduchou presnosťou hodnôt s pohyblivou rádovou čiarkou (hodnoty RGBA súčasne okolo ôsmeho cieľa vykresľovania) v zadnej časti oblasti priblíženia a CUDA podporuje bodové položky - číslo počet záznamov nie je obmedzený -aká adresa.
Cieľom OpenCL je doplniť OpenGL a OpenAL, čo sú Galouzovské kritické štandardy pre triviálnu počítačovú grafiku a zvuk, využívajúce možnosti GPU.
OpenCL je súčasťou a podporuje neziskové konzorcium Khronos Group, ktoré zahŕňa mnoho skvelých spoločností vrátane Apple, AMD, Intel, nVidia, Sun Microsystems, Sony Computer Entertainment a ďalších.
CAL/IL (výpočtová abstraktná vrstva/stredne pokročilý jazyk)
ATI Stream Technology je súbor hardvérových a softvérových technológií, ktoré umožňujú využitie grafických procesorov AMD spolu s centrálnym procesorom na zrýchlenie bohatých aplikácií (nielen grafických).
Medzi oblasti, na ktoré sa zameriava ATI Stream, patria príspevky, ktoré sú prínosom pre výpočtové zdroje, ako je finančná analýza a spracovanie seizmických údajov.
Použitie streamovacieho procesora umožnilo 55-násobne zvýšiť rýchlosť určitých finančných výdavkov s rovnakými riešeniami, aké riadi len centrálny procesor.
Technológia ATI Stream od NVIDIA sa nepovažuje za silného konkurenta.
CUDA a Stream sú dve rôzne technológie, ktoré stoja na rôznych úrovniach vývoja.
Počnúc hrudníkom v roku 2009 je softvérový model CUDA publikovaný na 269 univerzitách po celom svete.
V Rusku sa počiatočné kurzy CUDA vyučujú na univerzitách v Moskve, Petrohrade, Kazani, Novosibirsku a Perme, Medzinárodnej univerzite prírody a humanity „Dubna“, Spojený inštitút jadrového výskumu, Moskovský inštitút elektronickej technológie, Ivanovo State Energy Univerzita, BSTU im.
V. G. Shukhova, MSTU im.
Bauman, RHTU im. Mendelev, Ruské vedecké centrum „Kurčatovov inštitút“, Medziregionálne superpočítačové centrum Ruskej akadémie vied, Technologický inštitút Taganroz (TTI PFU). GPU wiki na výpočet dodatočnej pomoci C++ AMP Doteraz sme v diskutovaných metódach paralelného programovania videli iba jadrá procesorov..
Pridali sme zručnosti pre paralelizáciu programov naprieč viacerými procesormi, synchronizáciu prístupu k zdrojom s vysokými zdrojmi a používanie primitív vysokorýchlostnej synchronizácie bez blokovania.
Existuje však aj iný spôsob paralelizácie programov -
Grafické procesory (GPU)
Dnešné grafické procesory vyžadujú čo i len malý súbor inštrukcií.
To zahŕňa dôležité úvahy: dostupnosť funkcií, dostupnosť podporovaných dátových typov, dostupnosť knižničných funkcií a iné.
Niektoré operácie, ako napríklad inteligentné prechody, môžu byť podstatne drahšie ako podobné operácie, ktoré stoja na základných procesoroch.
Je zrejmé, že prenos veľkého množstva kódu z procesora na grafický procesor s takouto mysľou prináša značné výhody.
Počet jadier v priemernom grafickom procesore je podstatne vyšší ako v priemernom základnom procesore.
Úlohy sú však príliš malé a neumožňujú rozložiť veľké množstvo častí, aby ste mohli využiť stagnáciu grafického procesora.
Podpora synchronizácie medzi jadrami grafického procesora na dokončenie jednej úlohy, bez ohľadu na to, aká malá je, a celý deň medzi jadrami grafického procesora na dokončenie rôznych úloh.
Toto usporiadanie sa spolieha na synchronizáciu grafického procesora s primárnym procesorom.
Ide o napájanie, ktoré je vhodné pre spustenie grafického procesora?
Upozorňujeme, že nie každý algoritmus je vhodný na spustenie na grafickom procesore.
Napríklad grafické procesory neumožňujú prístup k vstupným/výstupným zariadeniam, takže nemôžete získať produktivitu z programov, ktoré sťahujú RSS kanály z internetu za cenu grafického procesora.
Na grafický procesor je však možné preniesť veľké množstvo výpočtových algoritmov a zabezpečiť ich masívnu paralelizáciu. Nižšie je uvedených niekoľko aplikácií takýchto algoritmov (tento zoznam nie je ani zďaleka vyčerpávajúci):, Є výpočtové zariadenia.
S pomocou ovládača DirectX 11 framework C++ AMP dynamicky deteguje všetky problémy.
Súčasťou skladu C ++ AMP je aj softvérový emulátor a emulátor založený na primárnom procesore WARP, ktorý slúži ako záložná možnosť v systémoch bez grafického procesora alebo s grafickým procesorom, s výnimkou absencie ovládača DirectX 11, a jadrá rámca vikory a inštrukcie SIMD.< length; ++i) { result[i] = first[i] + exp(second[i]); } }
A teraz prejdime k vývoju algoritmu, ktorý možno ľahko paralelizovať na vizualizáciu na grafickom procesore.
Nižšie uvedená implementácia berie dva vektory rovnakej hodnoty a vypočítava bodový výsledok. Je ľahké zistiť, čo je jednoduchšie: Void VectorAddExpPointwise (float * prvý, float * druhý, float * výsledok, int dĺžka) (pre (int i = 0; i
Ak chcete paralelizovať tento algoritmus na primárnom procesore, musíte rozdeliť rozsah iterácie na niekoľko podrozsahov a spustiť jedno vlákno pre každý z nich.
Teraz môžeme sledovať kožnú časť kódu okremo.
Je veľmi dôležité, aby sa zachovala pôvodná podoba slučky head, hoci cyklus for bol na začiatku nahradený funkciou parallel_for_each. Princíp transformácie slučky na cyklickú funkciu alebo metódu pre nás v skutočnosti nie je novinkou – takáto technika bola predtým demonštrovaná pomocou metód Parallel.For() a Parallel.ForEach() z knižnice TPL. Potom sa vstupné dáta (parametre prvý, druhý a výsledok) zabalia do inštancií
array_view . Trieda array_view sa používa na spracovanie údajov a ich prenos do grafického procesora (skratka).
Tento parameter šablóny označuje typ údajov a ich veľkosť.
Ak chcete stiahnuť pokyny na grafickom procesore, ktorý spracováva údaje z pôvodného procesora, musíte údaje skopírovať aj do grafického procesora, pretože väčšina súčasných grafických kariet nezaťažuje prístavby silnou pamäťou.<1>Túto úlohu vykonávajú inštancie array_view – tie zabezpečia, aby sa dáta kopírovali čo najviac a len ak je to absolútne nevyhnutné.
Keď grafický procesor vyradí údaje, údaje sa skopírujú späť. Vytvorením inštancií array_view s argumentom const zaručujeme, že prvá a druhá budú skopírované do pamäte GPU a nebudú skopírované späť. Nakoniec metóda VectorAddExpPointwise zaisťuje, že výsledky výpočtu z array_view avResult, vygenerovaného grafickým procesorom, sa skopírujú späť do poľa výsledkov.
Tu uzatvárame naše prvé poznatky zo sveta C ++ AMP a teraz sme pripravení na ďalšie správy, ako aj užitočnejšie aplikácie na demonštráciu výhod rýchlejších paralelných výpočtov na grafickom procesore.
Súčet vektorov nie je najlepším algoritmom a nie je ani najlepším kandidátom na demonštráciu použitia grafického procesora cez vysoké režijné náklady na kopírovanie údajov.
Ďalší vták bude mať dva väčšie zadky.
multiplikačná matica< m; ++i) { for (int j = 0; j < n; ++j) { int sum = 0; for (int k = 0; k < w; ++k) { sum += A * B; } C = sum; } } }
Prvým „relevantným“ zadkom, na ktorý sa pozrieme, je viacnásobná matica.
Aby sme to implementovali, použijeme jednoduchý algoritmus násobenia kubickej matice, a nie Strassenov algoritmus, ktorý je blízky kubickej ~ O (n 2,807).
Preto môže byť užitočné paralelizovať dve vonkajšie slučky, pričom vnútorná slučka zostane nedokončená:
Void MatrixMultiply (int * A, int m, int w, int * B, int n, int * C) (zobrazenie poľa
Pokiaľ ide o oddelenie úloh na grafickom procesore, možno to považovať za jednoduchú záležitosť implementácie internej slučky.
Došlo mi, že už to tak nebude.
Blog Native Concurrency, o ktorom už bola reč, ukazuje, ako modelovať gravitačné interakcie medzi časticami.
Modelovanie zahŕňa nekonečné množstvo tvárí;
Na povrchu pokožky sa vypočítajú nové hodnoty prvkov vektora zrýchlenia pre oblasť pokožky a potom sa určia ich nové súradnice.
Struct častice (poloha float4, rýchlosť; // implementácie konštruktora, kopírovacieho konštruktora a // operátora = s vynechaním obmedzenia (amp), aby sa ušetrilo miesto);
Predtým, ako dokončíme túto časť, musíme predstaviť ešte jednu dôležitú vlastnosť rámca C++AMP, ktorá môže ďalej zlepšiť produktivitu kódu, ktorý beží na GPU. Podporované sú grafické procesory programovanie dátovej vyrovnávacej pamäte (Často hodnosti pamäť (zdieľaná pamäť)
). Hodnoty, ktoré má vaša vyrovnávacia pamäť, sú bezproblémovo kombinované so všetkými tokmi ikonografie v jednej mozaike (dlaždici). Vďaka mozaikovej organizácii pamäte môžu programy založené na frameworku C++ AMP čítať dáta z pamäte grafickej karty do pamäte, ktorá oddeľuje mozaiky a potom k nim pristupovať z niekoľkých vlákien bez toho, aby tieto dáta znovu extrahovali z pamäťovej grafickej karty. .
Prístup k pamäti, v ktorej sú mozaiky dokončené, je približne 10-krát rýchlejší ako pamäť grafickej karty.<2>Inými slovami, máte dôvody pokračovať v čítaní.<2,2>Aby sa zabezpečilo spustenie dlaždicovej verzie paralelnej slučky, odovzdá sa metóda parallel_for_each<2,2>rozsah_dlaždíc domény<2,2>, ktorý rozdeľuje objekt bohatého rozsahu na fragmenty bohatej mozaiky, a parameter lambda tiled_index, ktorý označuje globálne a lokálne ID vlákna v strede mozaiky.

Napríklad maticu 16x16 možno rozdeliť na 2x2 časti mozaiky (ako je znázornené na obrázku nižšie) a potom odovzdať funkcii parallel_for_each:
Rozsah<2>matrica(16,16); dlaždicový_rozsah dlaždiceMatrix = matrica.dlaždica
();
paralelný_pre_každý(dlaždícMatrix, [=](index_dlaždíc<2,2>idx) obmedziť (amp) (// ...));
Je zrejmé, že akékoľvek výhody zdieľania inej pamäte možno získať iba počas synchronizácie prístupu k rovnakej pamäti; To znamená, že vlákna sa nemusia konvertovať na pamäť, kým nie sú inicializované jedným z nich. Synchronizácia streamov v mozaike je koordinovaná s ďalšími objektmi
dlaždicová_bariéra<2,2>(tipujem triedu Barrier z knižnice TPL) - môžu vydržať len do zavolania metódy tile_barrier.Wait(), ktorá je ovládaná len vtedy, ak všetky vlákna volajú tile_barrier.Wait.
napríklad:
Parallel_for_each(dlaždícMatrix, (index_dlaždíc
Aby sme to implementovali, použijeme jednoduchý algoritmus násobenia kubickej matice, a nie Strassenov algoritmus, ktorý je blízky kubickej ~ O (n 2,807). Podstatou opísanej optimalizácie je, že kožné vlákno v mozaike (pre blok 16 x 16 sa vytvorí 256 vlákien) inicializuje svoj prvok v 16 x 16 lokálnych kópiách fragmentov výstupnej matice A a B. Kožný tok v mozaika vyžaduje iba jeden riadok a jeden rad radov blokov, inak všetky toky pretečú naraz do radu skinov a do stĺpca skinu 16-krát. Tento prístup v podstate znižuje množstvo úložného priestoru potrebného pre hlavnú pamäť. Na výpočet prvku (i, j) vo výslednej matici potrebuje algoritmus i-tý riadok prvej matice a j-tý riadok ďalšej matice. Ak sú vlákna mozaiky 16x16 znázornené v diagrame a k = 0, tieňované oblasti v prvej a ďalších maticiach sa načítajú do pamäte, ktorá sa rozdelí. Doteraz tento článok demonštroval iba aplikácie v jazyku C++, proto a množstvo spôsobov využitia grafického procesora v spevnených aplikáciách. Jedným zo spôsobov je použitie nástrojov interoperability, ktoré vám umožnia preniesť prácu z jadier GPU do komponentov C++ na nízkej úrovni. Je vhodný najmä pre tých, ktorí chcú používať framework C++ AMP alebo môžu chcieť použiť hotové komponenty C++ AMP v balených doplnkoch. Ďalším spôsobom je použitie knižnice, ktorá priamo spolupracuje s grafickým procesorom a jadrom kódu. V súčasnosti je otvorených tucet takýchto knižníc. Napríklad GPU.NET a CUDAfy.NET (urážané komerčnými návrhmi). Nižšie je uvedený príklad z GPU.NET GitHub, ktorý demonštruje implementáciu skalárneho spracovania dvoch vektorov: Verejné statické neplatné MultiplyAddGpu (dvojité a, dvojité b, dvojité c) (int ThreadId = BlockDimension.X * BlockIndex.X + ThreadIndex.X; int TotalThreads = BlockDimension.X * GridDimension.X; for (int ElementIdx = ThreadId; ElementIdx Dnešné GPU sú obludné tajné beštie, ktoré spotrebúvajú gigabajty dát. Prefíkaný človek však, ako keby výpočtové tlaky nerástli, príde s problémom, ktorý sa stáva čoraz zložitejším, takže príde moment, keď si musíte priznať, že optimalizácia je potrebná 🙁 V tomto článku sú popísané základné pojmy, aby sa uľahčila orientácia v teórii optimalizácie gpu a základné pravidlá, na ich pochopenie bolo potrebné sa trochu pohrať. vysoká priepustnosť pamäteŠírka pásma pamäte - Koľko informácií - bit alebo gigabajt - možno preniesť za jednu hodinu, sekundu alebo cyklus procesora. Jednou z úloh optimalizácie je maximalizácia priepustnosti budovy – zvýšenie displejov priepustnosť (V ideálnom prípade to bude kvôli staršej šírke pásma pamäte). latencia zmeny – oneskorenie medzi operáciami Latencia - hodinový interval medzi okamihmi, keď regulátor požaduje konkrétny zostatok pamäte, a okamihom, keď sú údaje dostupné procesoru na zadávanie pokynov. zmeniť počet vlákien v bloku zvýšiť počet skupinových blokov Zdroje GPU Vikoristannya navrchu – obsadenosť GPU V diskusiách na vysokej úrovni o optimalizácii sa často objavuje výraz - obsadenosť gpu alebo inak Uhádnem, čo je warp ( osnova
v terminológii NVidia, vlnoplocha
- v terminológii AMD) - sada vlákien, ktoré súčasne vykonávajú rovnakú funkciu jadra na procesore. Vlákna, organizované programátorom do blokov, sú rozdelené na warpy pomocou plánovača vlákien (blízko skinu multiprocesoru) - kým jeden warp funguje, druhý kontroluje spracovanie požiadaviek do pamäte atď.
Keďže toky warpu stále vedú k platbám a iní už zarobili všetko, čo mohli – môže ísť o neefektívne využitie výpočtového zdroja – ľudovo nazývaného nečinná práca. Kožný bod synchronizácie, kožné narušenie logiky môže viesť k takejto prestojovej situácii. Aby ste znížili prestoje multiprocesora počas warp hodiny: Minimalizujte čas čistenia baru minimalizovať divergenciu logiky vo funkcii jadra Ak chcete efektívne dokončiť túto úlohu, musíte zvážiť, ako sa osnova formuje (pre rôzne rozmery). Jadro sa spustí s blokmi s rozmermi 16 × 64. Prvá osnova pridá prvých a ďalších 16 prvkov, druhá osnova pridá tretí a štvrtý atď. Ako znížiť divergenciu (pamätajte - dezorganizácia nie je vždy príčinou kritickej straty produktivity) Grafické karty majú limit na počet vlákien, ktoré možno pridať do jedného multiprocesora, maximálny počet vlákien v jednom bloku, maximálny počet warp na jednom procesore, limit na rôzne typy pamäte atď. Všetky tieto informácie je možné vyžiadať buď programovo, prostredníctvom externého rozhrania API alebo prostredníctvom dodatočného nástroja zo súpravy SDK. Počet blokov/pracovných skupín vlákien je násobkom počtu stream procesorov Veľkosť bloku/pracovnej skupiny je násobkom veľkosti osnovy Vzhľadom na to, že absolútnym minimom sú 3-4 warps/wayfronty, ktoré sa každú hodinu točia na skin procesore, je múdre zmiznúť zo sveta – nie menej ako sedem wayfrontov. V mojej hlave sa všetky tieto detaily rýchlo spájajú, takže pre účely konfigurácie obsadenosti gpu NVidia predstavila nevyhovujúci nástroj - Excel (!) kalkulačku naplnenú makrami. Tam môžete zadať informácie o maximálnom počte streamov pre SM, počte registrov a veľkosti zdieľanej pamäte dostupnej na streamovacom procesore a zvolených parametroch pre spúšťanie funkcií - a môžete vidieť efektivitu zdieľaných zdrojov v percentách (a vy si na rozpoznanie vytrhnete vlasy na hlave Ak chcete použiť všetky jadrá, nemusíte mazať registre). Informácie o Wikoristane: http://docs.nvidia.com/cuda/cuda-c-best-practices-guide/#calculating-occupancy Operácie GPU a pamäte Otvorené optimalizácie pre 128-bitové operácie s pamäťou.) Môže to výrazne zlepšiť vašu produktivitu. Pri organizovaní vášho jadra – pamäť – obmedzený prístup – medzi prvky jedného radu pamäte, robot s prvkami zátky – to už nie je také efektívne.
“. Chcete viac podrobností? Mal som tú česť s osou pdf - alebo google pre predmet "
techniky spájania pamäte Vedúce miesto v kategórii „školské miesto“ je obsadené ďalšou pamäťovou operáciou - kópiu hostiteľskej pamäte v GPU
. Kopírovanie sa nevykonáva len tak, ale zo špeciálne určenej oblasti ovládača a systémovej pamäte: pri zapisovaní na kopírovanie údajov systém okamžite skopíruje údaje tam a potom ich nahrá do GPU.
Rýchlosť prenosu dát je obmedzená šírkou pásma zbernice PCI Express xN (kde N je počet dátových liniek), cez ktorú sa grafické karty pripájajú k hostiteľovi. Skopírovanie veľkého množstva pamäte na hostiteľovi vás však bude stáť veľa peňazí. Vikhid - vikorystuvati tzv pripnutá pamäť - oblasť pamäte je označená špeciálnym označením, takže operačný systém s ňou nemôže vykonávať žiadne operácie (napríklad preniesť na swap / presunúť podľa vlastného uváženia atď.). Prenos dát z hostiteľa na grafickú kartu prebieha bez účasti operačného systému - asynchrónne, cez DMA
– . (Priamy prístup do pamäte). Pre používateľov CUDA je dôležité oceniť tento koncept cuda potok Umožňuje spustiť viacero funkčných jadier na jednom zariadení alebo povoliť asynchrónne kopírovanie dát z hostiteľa do zariadenia pod kontrolou funkcií. OpenCL zatiaľ takúto funkcionalitu neposkytuje 🙁 Brucht za profilovanie: NVifia Visual Profiler je užitočný nástroj, ktorý analyzuje jadrá CUDA aj OpenCL. P.S. Ako komplexnejší proces optimalizácie môžem každému odporučiť google
sprievodca osvedčenými postupmi pre OpenCL a CUDA. Upravte parametre vizualizácie GPU Ak je vaše pridanie nepravdivé, znamená to, že niektoré alebo všetky snímky aktualizovanej obrazovky sa aktualizujú za menej ako 16 milisekúnd. Ak chcete vizuálne vidieť aktualizované snímky na obrazovke, môžete na zariadení povoliť špeciálnu možnosť (Profile GPU Rendering). Možno budete môcť vidieť, ako dlho trvá kreslenie rámov. Predpokladám, že musíte investovať do 16 milisekúnd. Táto možnosť je dostupná na zariadeniach so systémom Android 4.1.. Na zariadení aktivujte režim dávkovača. Na zariadeniach s verziou 4.2 je k dispozícii vyšší režim pre nahrávanie aplikácií. Ak chcete aktivovať, prejdite na Vývojár sa musí naučiť efektívne využívať grafický procesor (GPU), aby program nepodvádzal alebo nezrušil aplikáciu. naladený | O telefónoch A kliknite na riadok sedemkrát číslo zbierky Poďme sa pozrieť na väčšiu verziu grafu. Zelená čiara sa zobrazí za 16 milisekúnd. Aby sa dodržala rýchlosť 60 snímok za sekundu, celá grafika musí byť malá pod čiarou. V niektorých momentoch sa vynoríte za hranicu skvelého a budete bohatší ako zelená čiara.. To znamená programy galmuvaniya. Farba kože je čierna, fialová (Lollipop a vyššie), červená a oranžová. Jasná farba za hodinu ukazuje, že vikoryst sa vytvára a aktualizuje Zobraziť Červená farba má na vytvorenie hodinu. Na zariadeniach s verziou 4.2 je k dispozícii vyšší režim pre nahrávanie aplikácií. Ak chcete aktivovať, prejdite na Fialová časť predstavuje hodinu strávenú prenosom zdrojov vykresľovania do vlákna. Oranžová farba ukazuje, ako dlho trvalo procesoru vychladnúť, kým GPU dokončil svoju prácu. To je tiež zdrojom problémov pri veľkých hodnotách. Na zmenu zamerania na grafický procesor existujú špeciálne techniky. Nalagodit prekreslenie GPU displeja Ďalšie nastavenie vám umožňuje rozpoznať, ako často je tá istá časť obrazovky premaľovaná (takže aplikácia robota je zrušená). Znovu prejdite na (Debug GPU Overdraw), ktorá stopa by mala byť povolená. V okne vypúšťania vyberte možnosť Zobraziť záplatu zóny (Zobraziť oblasti prekreslenia). Nekrič! Niektoré prvky na obrazovke je možné zmeniť na vlastnú farbu. Obráťte sa na akýkoľvek doplnok a dávajte si pozor na jeho prácu. Farba zobrazuje problematické oblasti vašej rastliny. Nekrič! Ak sa farba navyše nezmenila, znamená to, že je všetko v poriadku. Nekrič! Nedochádza k prekrývaniu jednej farby na druhú. Čierna farba ukazuje, že jedna guľa je namaľovaná na vrchu spodnej gule. Dobre. Zelená farba - prelakovaná dva dni. Málo rád. Miesto po metóde setContentView() Kliknite na metódu, ktorá vám pomôže premaľovať obrazovku farebným motívom.
Tok rovnice, ktorá počíta prvok (i, j) v matici výsledku, sa zmení na čiastkové skalárne teleso z prvých k prvkov z i-tého riadku a j-tého stĺpca výstupných matíc.
Ako znížiť latenciu pomocou synchronizácie:

Ako už bolo povedané, nezabudnite venovať pozornosť stúpaniu!Vývojár sa musí naučiť efektívne využívať grafický procesor (GPU), aby program nepodvádzal alebo nezrušil aplikáciu.
Fialová časť predstavuje hodinu strávenú prenosom zdrojov vykresľovania do vlákna.
